An in-depth look at Visual Application Discovery & Analysis (VADA)
Introduction
One of the most exciting features in SquaredUp is Visual Application Discovery & Analysis (aka “VADA”) which allows you to automatically discover and map your applications and view live health states and performance across your entire application stack.
VADA is extremely powerful, providing complete cross-platform and multi-node visibility, but also beautifully lightweight, powered by your existing SCOM Agent and Data on Demand, meaning there are no new Agents and no continuous data collection or storage.
This, together with a completely flat commercial model, means VADA can be used for not just a handful of applications, but for all of your applications and is designed to be put directly into the hands of your users, removing the burden of application modelling from the SCOM Administrator.
What’s more, VADA is fully integrated with SCOM Distributed Applications (DAs), meaning you or your colleagues can model your apps using VADA and easily save and import them as DAs into SCOM.
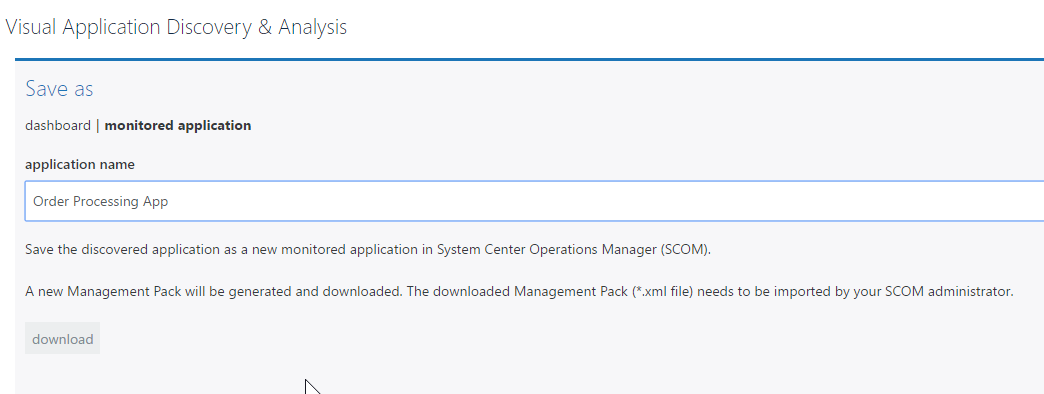
In turn, those DAs can be viewed using VADA any time you want to see health states and key performance metrics across the entire application stack.
This blog is designed to provide you with a detailed introduction to Visual Application Discovery & Analysis; what it is, how it works, how to use it and the value it delivers to you and your users.
Basic Requirements
To get up up-and-running with VADA you’ll need:
- SquaredUp, a lightweight IIS Web App which you install alongside your existing SCOM infrastructure, on-prem.
- ‘Data on Demand’ Management Packs –lightweight MPs for Windows & Linux / Unix respectively, containing a number of useful SCOM Agent Tasks which we’ve made freely available to the Community and publicly available on GitHub.
How it works: The basics
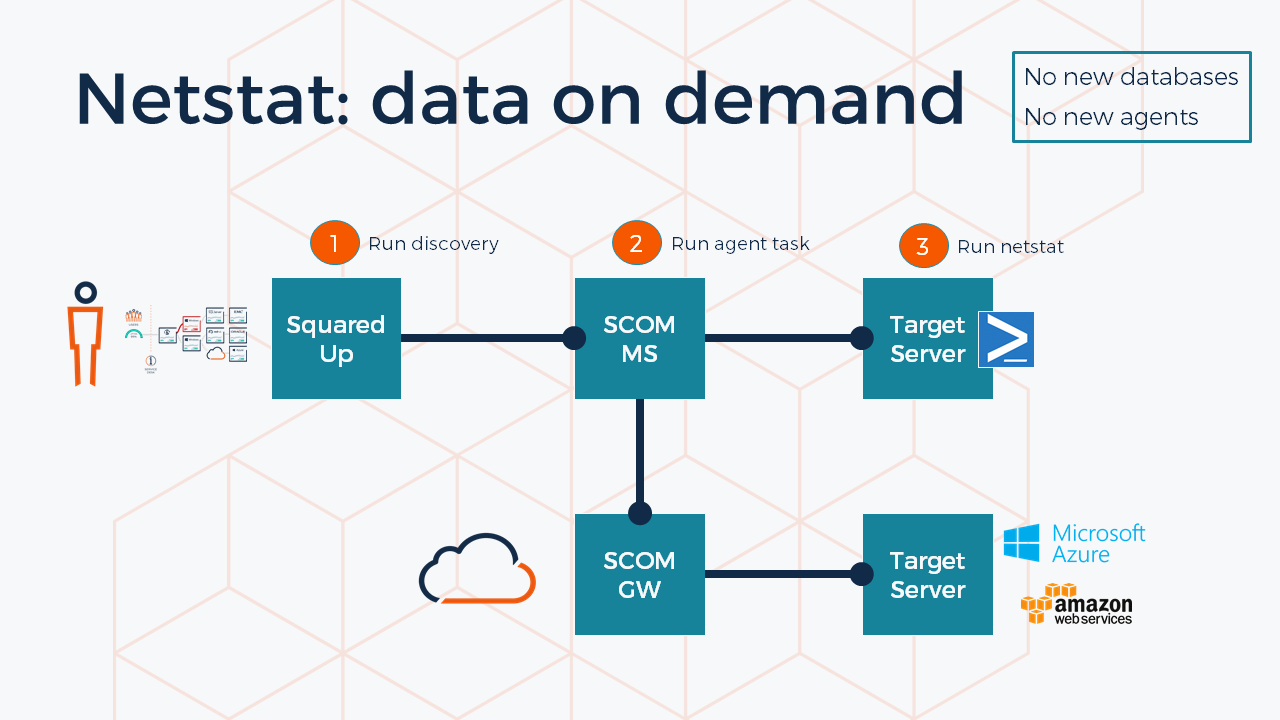
VADA is designed to be as simple and lightweight as possible and is powered by SCOM Agent Tasks, which are run on-demand.
Among the Agent Tasks included in the Data on Demand MP are ‘Get Netstat’ Tasks for Windows & Unix, and these are run on a node when VADA discovery is performed against it.
VADA then uses that Netstat information to dynamically map connections between your nodes, using advanced modelling algorithms.
Getting underway with VADA: A detailed walk-through
To use VADA, simply navigate to any node that supports discovery (i.e. Windows or Unix node and not, for example, a Load Balancer) and click on the ‘App Discovery’ tab.
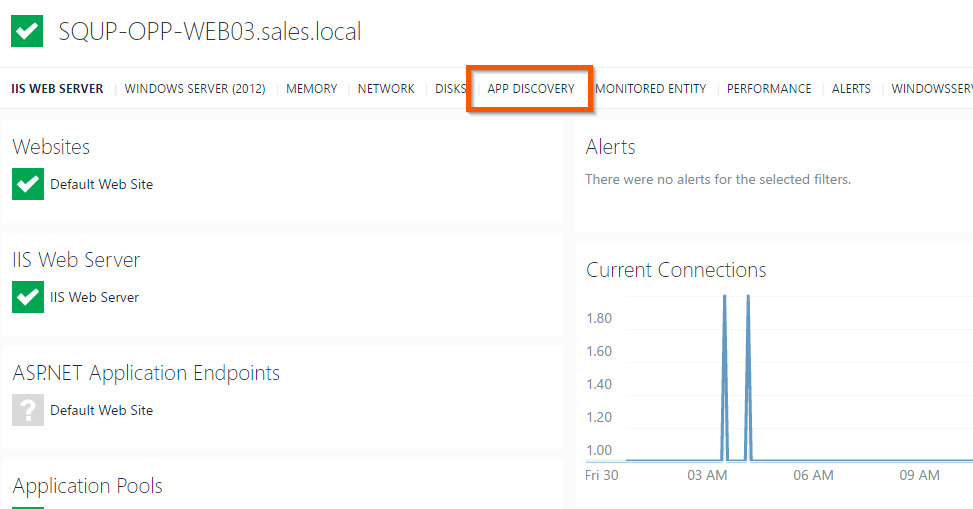
As soon as you do, VADA will automatically perform discovery on that node, running the GetNetstat Agent Task on-demand.
By default, VADA only shows out-going connections from a node, but you can easily expand in-coming connections too, as we’ll see a little later.
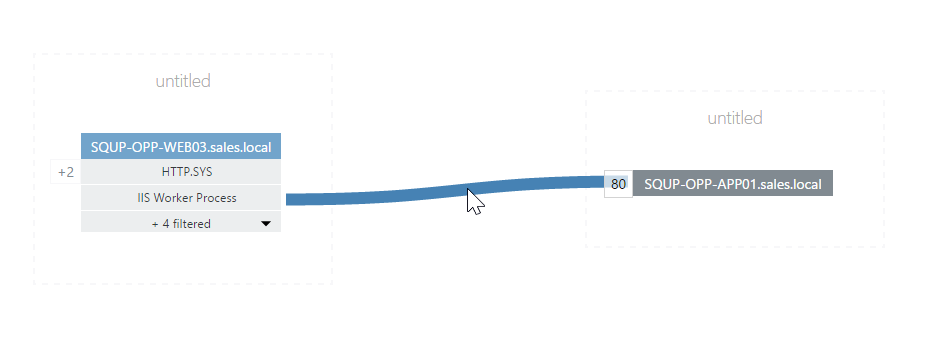
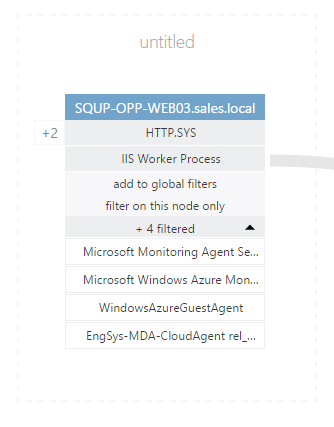
In the example below, we can see that;
- Web03 is communicating with App01 via IIS Worker Process on Port 80.
- Four additional out-going processes have been filtered out by default.
- There are two incoming HTTP.SYS connections.
- VADA has placed the two nodes into distinct Groups (a.k.a. tiers), which at this point are untitled.
Filtering
Before we move on, let’s look at the concept of filtering, which is key to ensuring that VADA paints a meaningful picture of your applications and ensuring you’re not simply overwhelmed by noise and irrelevant infrastructure data.
Filtering allows you to remove various processes from your VADA topologies, allowing you to easily exclude commonplace or unrelated services from your application discovery. Obvious examples would be tools like Configuration Manager, backup software like DoubleTake or Veeam and indeed SCOM itself. In others words, common processes running against your nodes but which don’t form part of the application itself.
At any stage, we can filter or unfilter processes from a discovered node.
Filtering can be performed on a global or a local basis and your global filters can be easily, centrally managed.
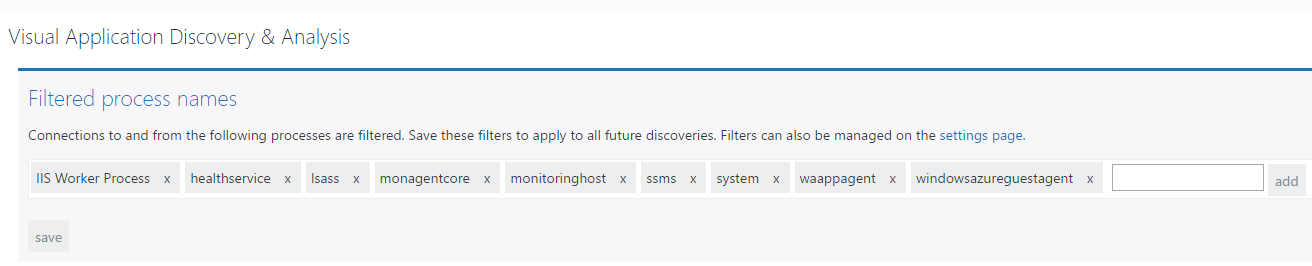
From a practical perspective, we’d suggest that a SCOM Administrator applies global filters to the relevant processes in your environment before putting VADA into the hands of your users, so that they start their discoveries looking at as clean a picture as possible.
Modelling your app
With the requisite filtering in place, we can start to model our app.
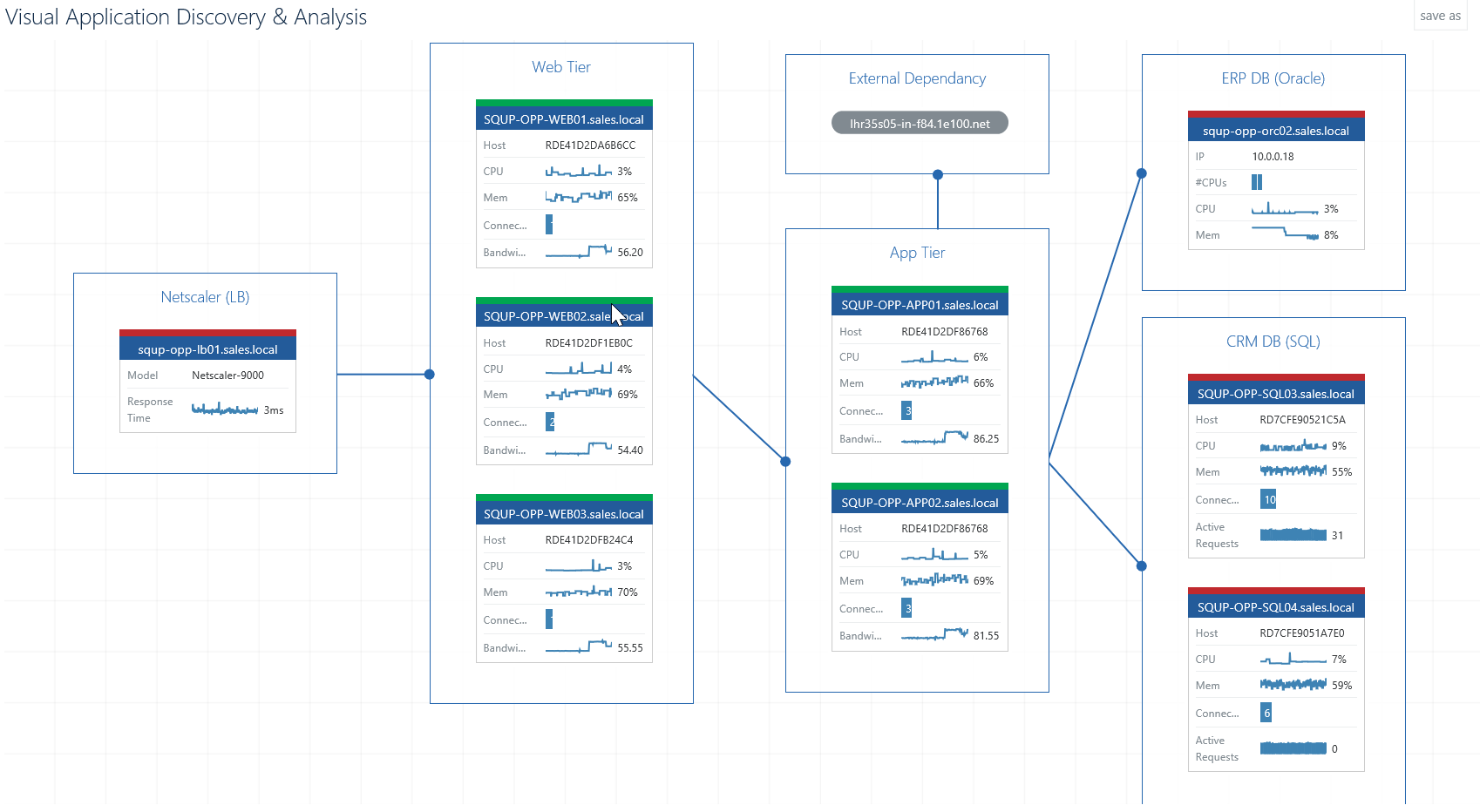
Firstly, by clicking on the small + to open out the incoming connection, we see that Web01 is behind a Load Balancer, LB01 (from which further discovery is not currently supported).

We can also take the opportunity to give titles to our various tiers, and you’ll notice that the various tiers become more clearly defined as we do so.
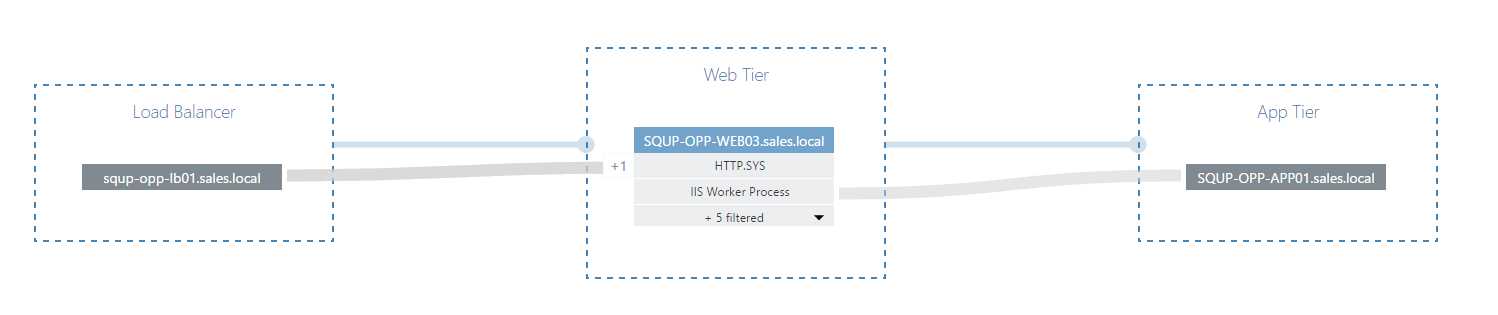
Of course, because discovery isn’t limited to a single node, we can continue run discovery on additional nodes.
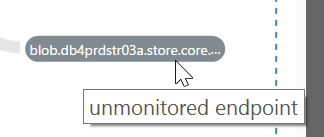
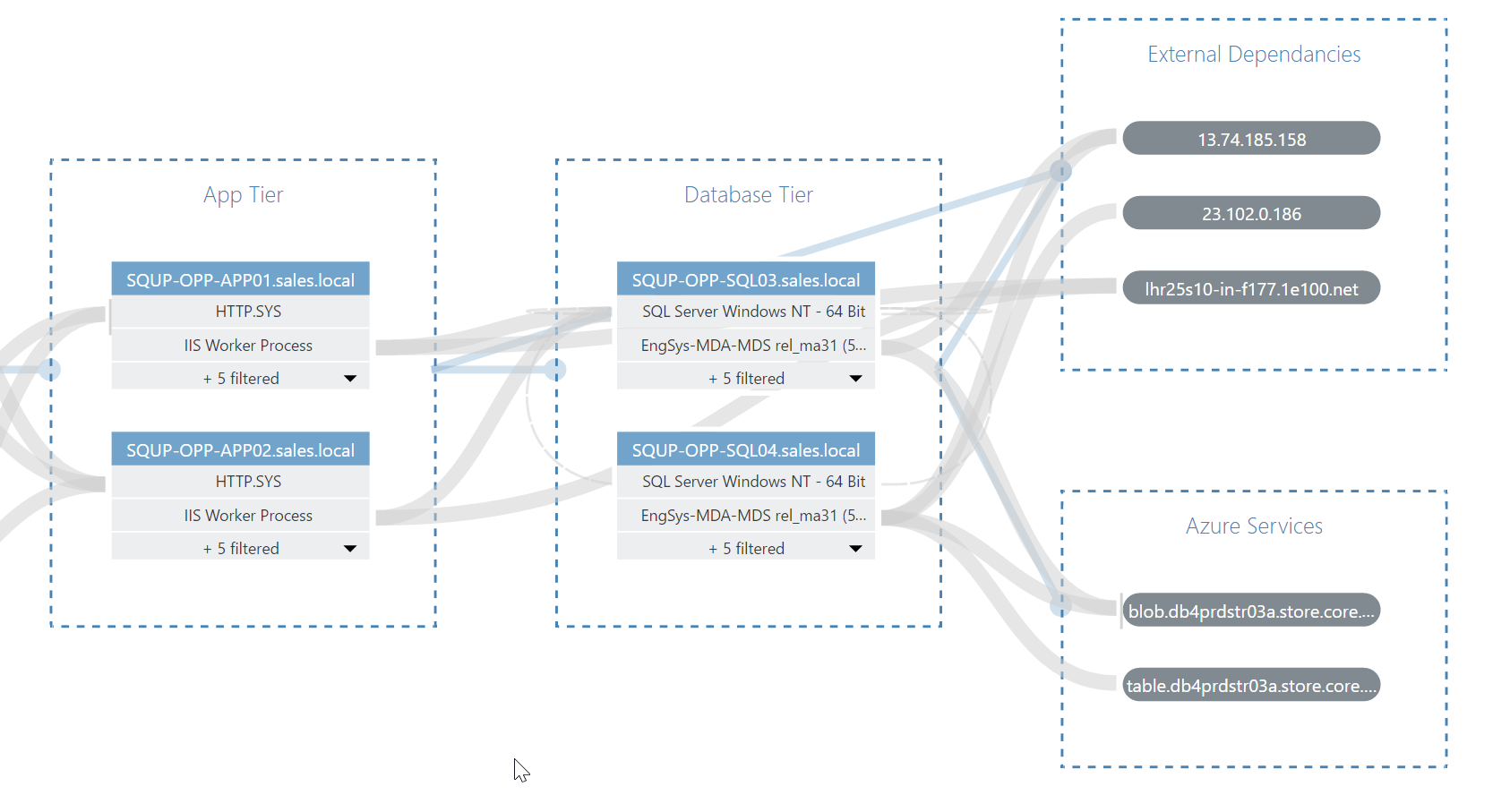
VADA is capable of discovering not only nodes that are already monitored by SCOM (shown as a grey, sharp-cornered rectangle) but also unmonitored end-points (shown as a grey rounded-rectangle); this means VADA is also great for discovering;
(a) unmonitored nodes that should be added to SCOM
(b) revealing external dependencies that your app relies upon and which should therefore be incorporated into your monitoring strategy (for example, by setting up a synthetic transaction against a third-party web dependency).
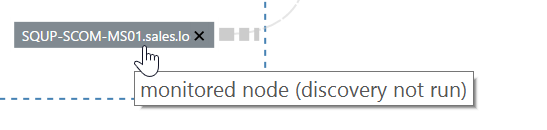
You can also manually remove any discovered nodes or dependencies that you don’t want to be a part of your application model.
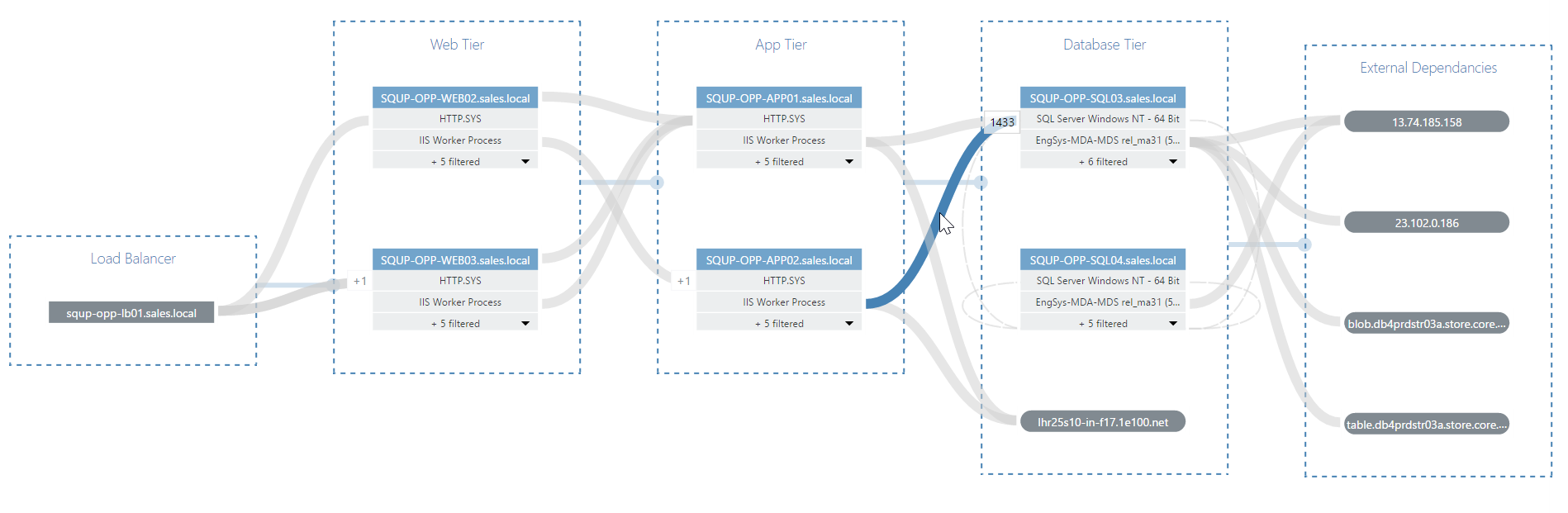
VADA will also automatically create Groups and place individual nodes into what it believes are the correct tiers / groups, but you can easily adjust this manually, simply by dragging a node from one tier to another.
Similarly, you can manually add additional tiers of your own and even create vertically aligned tiers where appropriate.
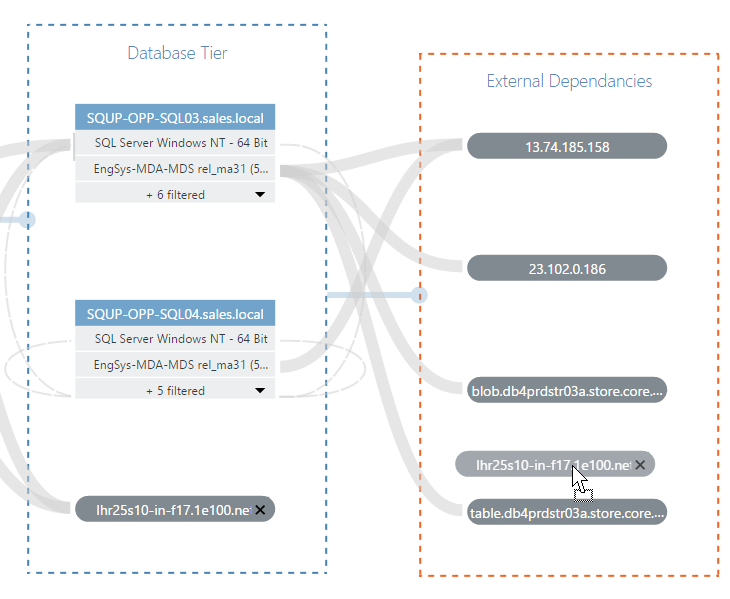
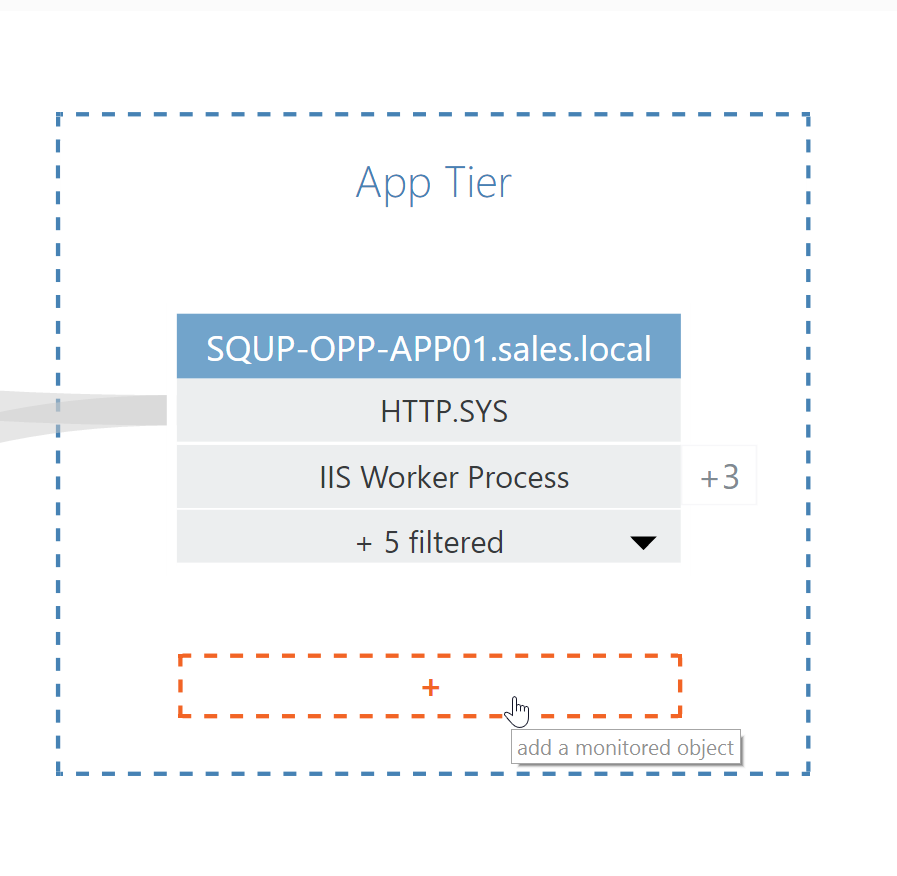
One limitation of VADA is that, because it’s run on-demand, you are reliant on there being active communication between nodes at the point of discovery in order for the connection to be discovered. Clearly, there are certain scenarios where this may lead to a node being excluded from an application topology; for example, if an application includes a server that runs a batch job overnight, or if a server that normally forms part of the application has temporarily been shut-down for maintenance.
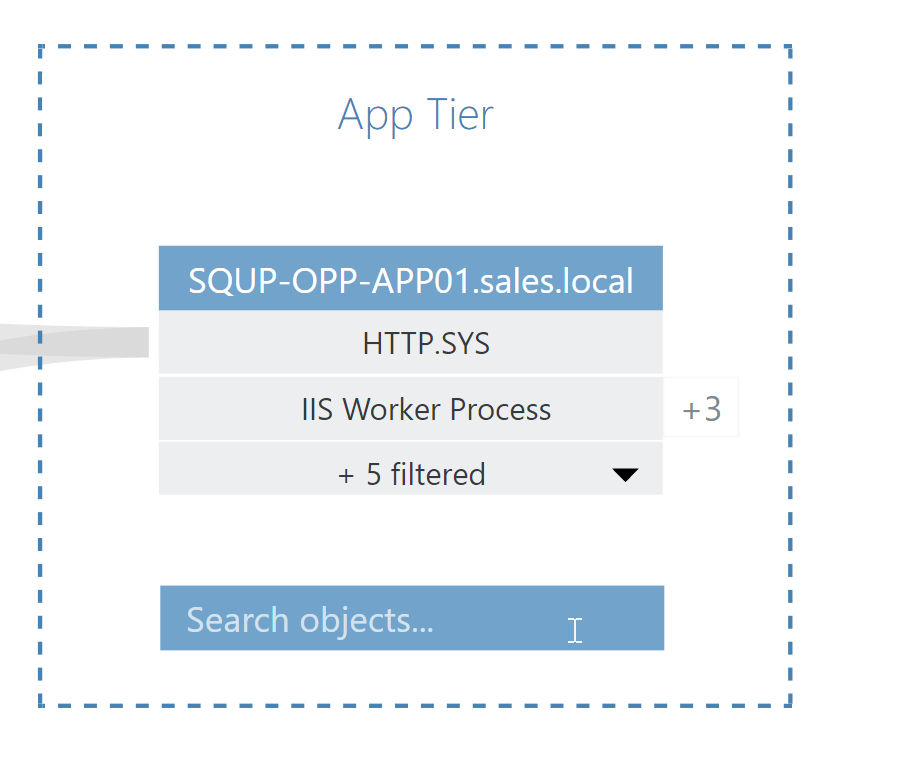
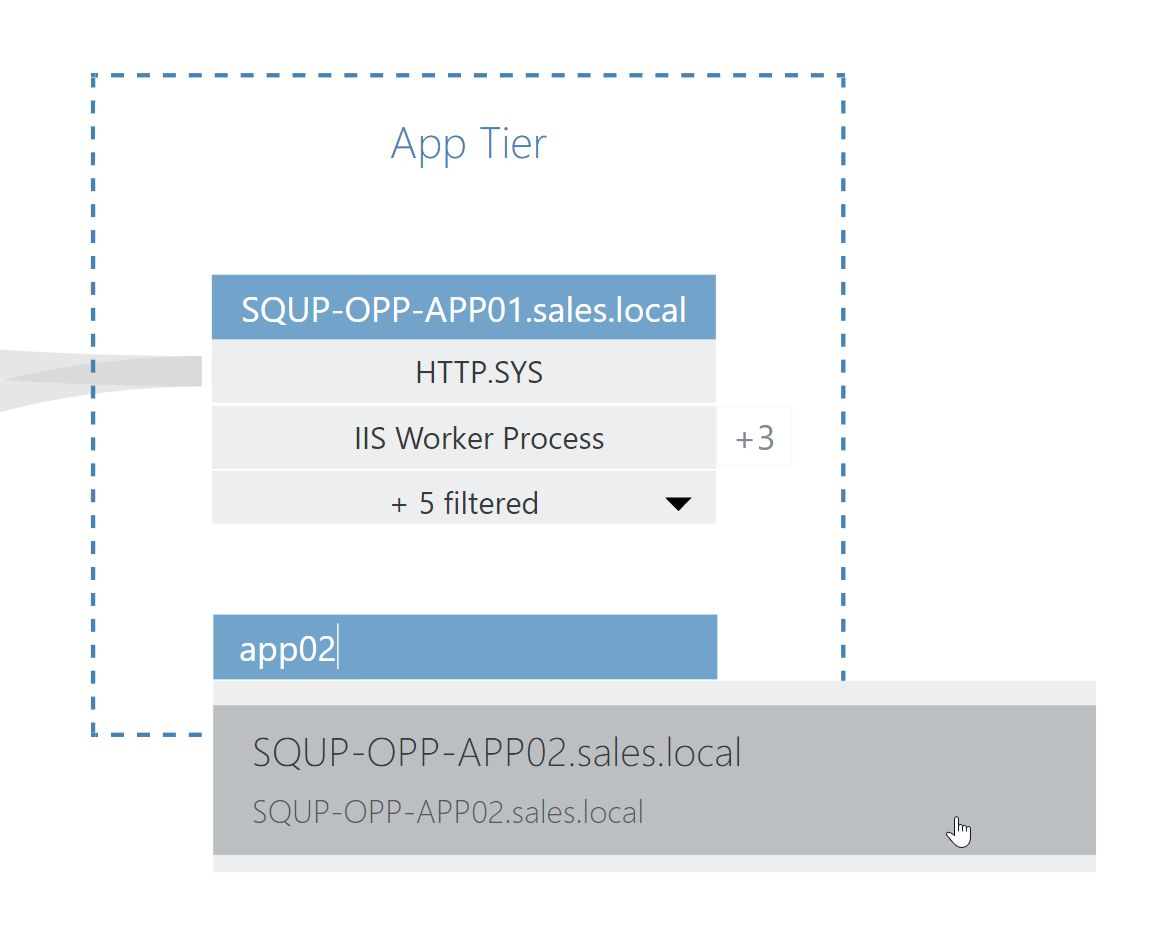
However, VADA makes it easy to incorporate these known dependencies into your application topology with the ability to manually add nodes, assisted by a fast, simple search function.
Saving as a Distributed Application (DAs)
Once the application has been modelled using VADA, it can be imported into SCOM as a Distributed Application. A one-click download generates and exports a new .xml Management Pack ready for import, including the grouping to ensure those are created as Component Groups in the DA.
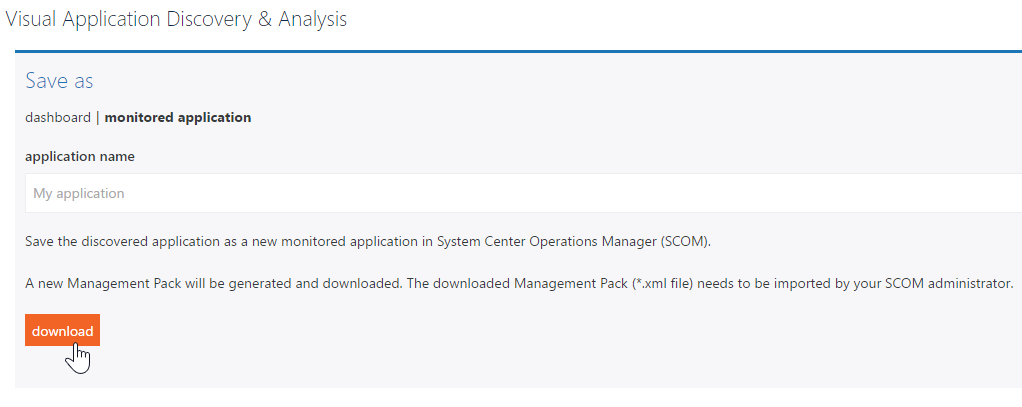
This has deliberately been left as a manual step so that application owners and other non-SCOM admins can model applications but the SCOM Administrator maintains complete control over importing Management Packs and creating DAs.
Creating your application as a DA within SCOM brings a number of benefits, including simplifying alert notification and allowing for easier scoping via Role Based Access Control.
Best of all though, by giving application context to your SCOM infrastructure data, SquaredUp can then use that structure to pull in data from other sources like ServiceNow, OMS, Service Manager and many more, all within the context of your applications. For example, instead of having just a sea of unstructured data within, say, OMS Log Analytics, by discovering your applications with VADA, easily defining them as DAs within SCOM and accessing them via SquaredUp, this means that when troubleshooting application performance issues you can seamlessly pull in fantastic, value-add data from OMS like recent log-ons or software updates for that precise application, all within a single pane of glass. That's a big topic all of it's own though, so stay tuned for a more detailed walk-through of that coming soon.
Of course, an key additional benefit of saving your discovered applications back to SCOM discovery is that, by using VADA in Analyse mode, you can then immediately view live health states across the entire application without having to model the application each time.
Analyse!
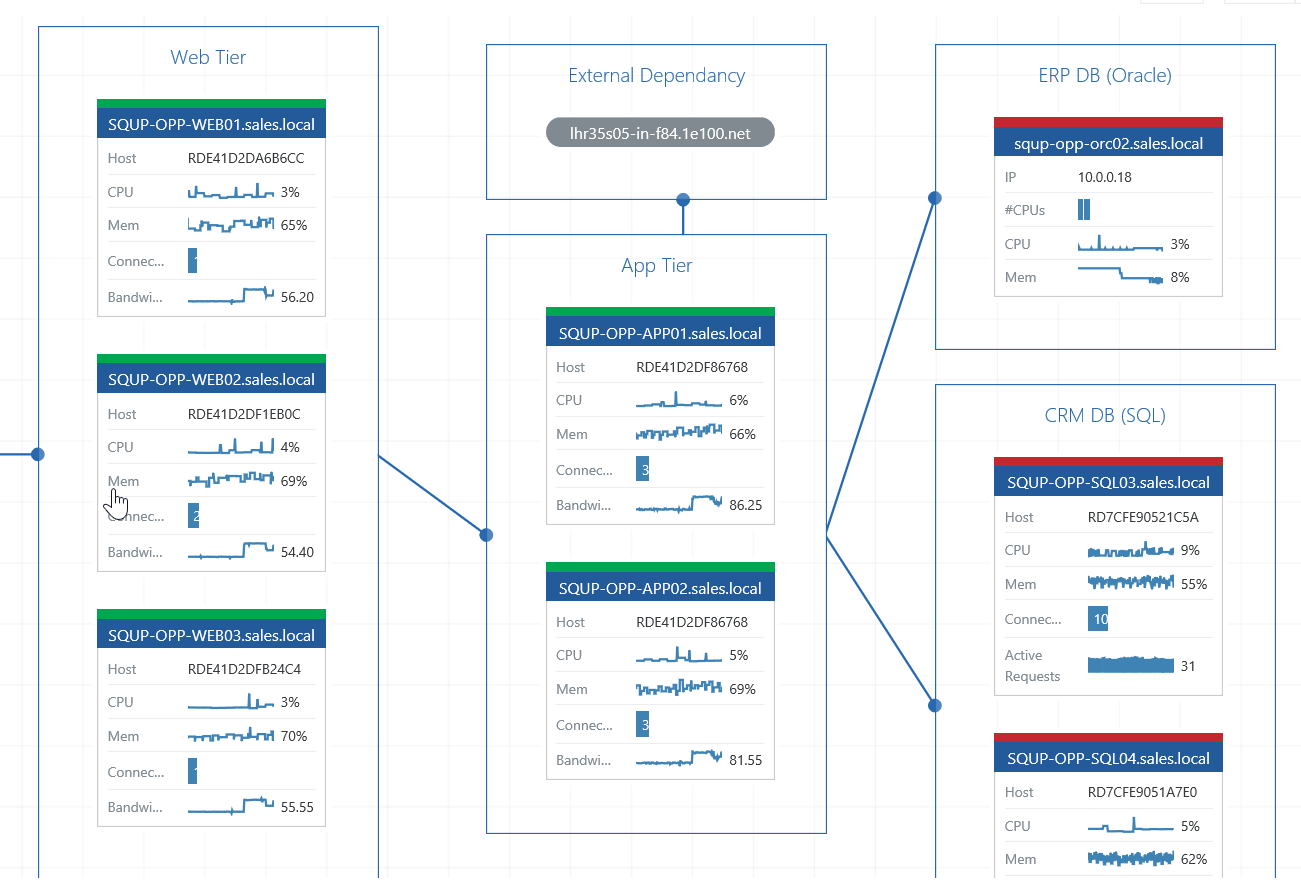
We called the feature Visual Application Discovery and Analysis for a reason; the real magic of VADA happens when you hit the ‘analyze’ button and your application health comes to life.
The beauty of VADA is that it uses all your existing SCOM data to provide you with a complete picture of the health of your application, right across the entire stack. As with the Discovery element, this means VADA allows you to make the most of your existing tools and datasets rather than requiring you to install heavyweight new tools, new agents, connect to cloud services or undertake significant new data collection.
Here, the unique capabilities of SCOM as a cross-platform monitoring tool really come into their own, allowing you to provide in-depth monitoring across disparate technology stacks and deliver complete visibility of the performance of all your apps, from a single, centralised tool.
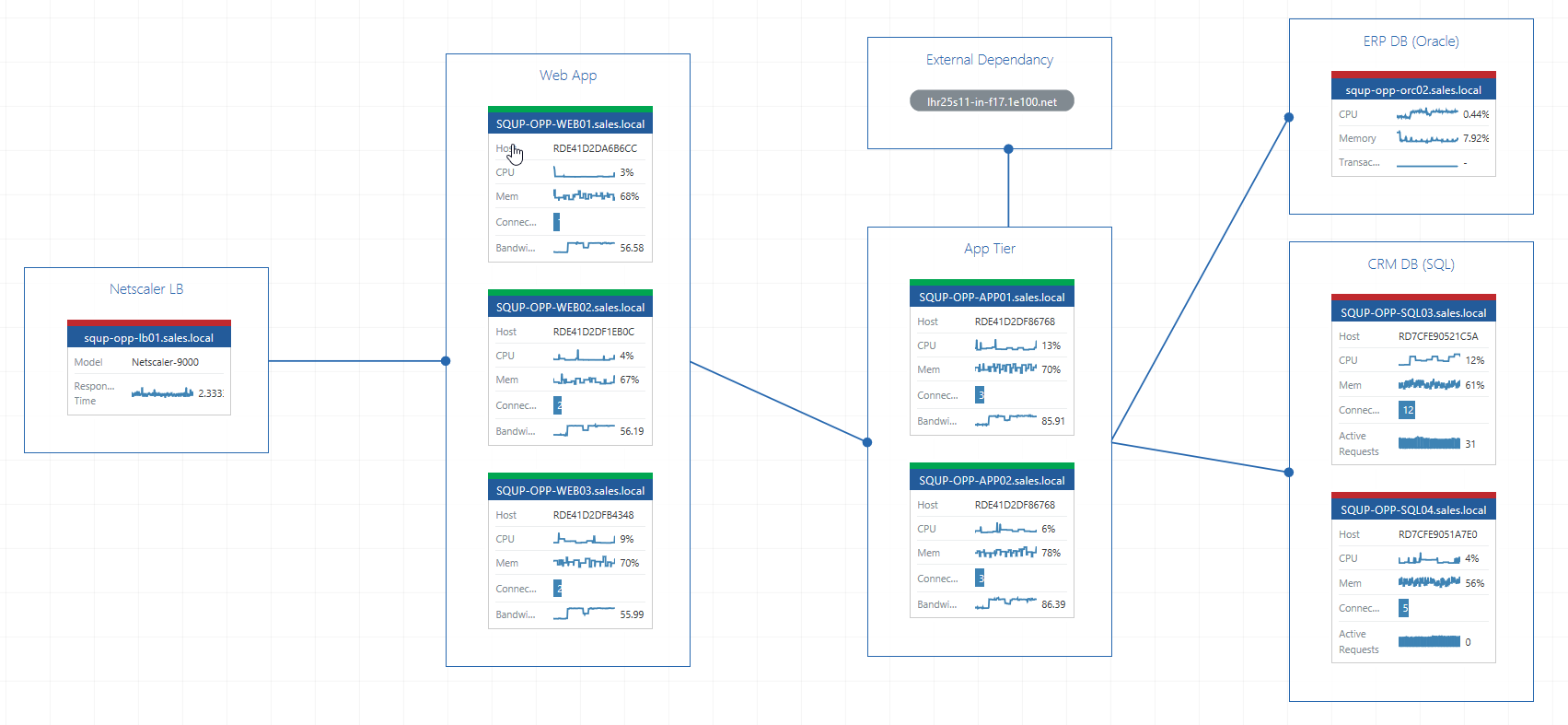
For example, in the screenshot above, you can see that we’re monitoring multiple different platforms; a Citrix Netscaler Load Balancer, IIS Web Servers, Windows App Servers, SQL Databases and an Oracle Database.
With complete visibility now provided by VADA, troubleshooting performance issues and pinpointing from across complex applications becomes far quicker.
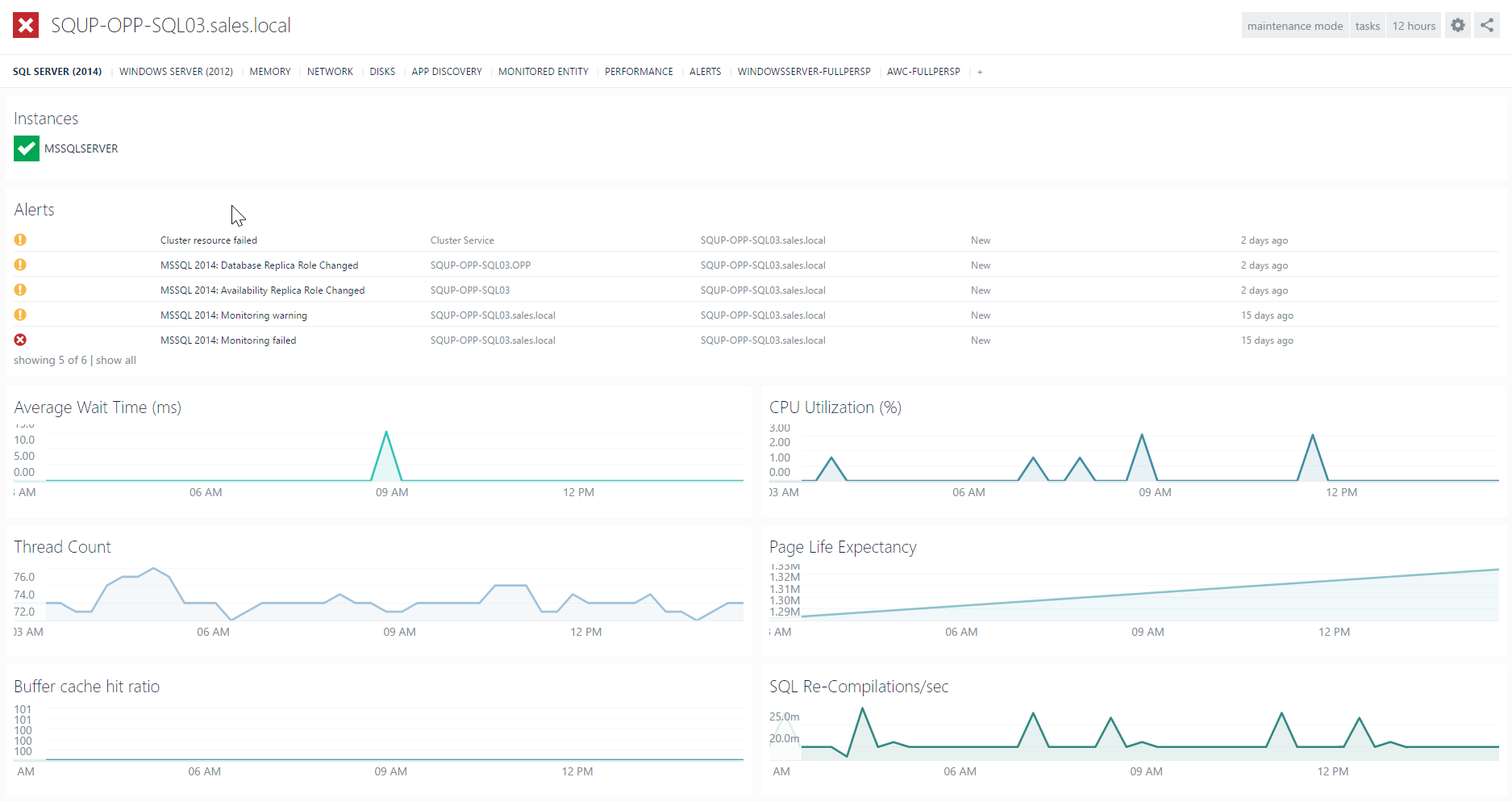
What’s more, we can drilldown into any of these nodes to get to all the rich underlying data, including the long-term performance data available from the Data Warehouse.
Key Scenarios
VADA is a hugely valuable feature for many different scenarios;
- Rapid application discovery and mapping, including DA creation.
- Easily pinpoint and troubleshoot performance issues across your entire application stack, including complex, cross-platform applications.
- Discovering unmonitored nodes / end-points.
- Discovering external dependencies and incorporating them into your application model.
- Dependency discovery for patching or business continuity scenarios
- Migration Planning
Pros and Cons
VADA is designed to take on the problem of application monitoring within Enterprise IT; namely, delivering comprehensive visibility into application performance across the hundreds, sometimes even thousands, of applications within a typical enterprise organisation. Accurate topologies of these applications and their dependencies are rarely known and, in most cases, the apps span several different technology stacks and therefore several different teams and specialists.
We’ve deliberately taken a lightweight approach to solving this problem, one that’s focused on delivering immediate results and value, one that doesn’t introduce complex new dependencies or infrastructure components but which instead allows you to make the most of your existing investments and datasets.
We think there are a number of very significant benefits to this approach, together with a few drawbacks.
The Pros
- No new agent required
- No new databases required
- No significant new data collection or data storage required
- No new infrastructure required
- No external / cloud dependencies, entirely on-prem
- Cross-platform support and visibility
- Health states and performance visible across entire apps, spanning multiple nodes
- Fully integrated with your existing SCOM data
- Fully integrated with existing SCOM DA model
- Very short time-to-value
- Easy to use, suitable for your users
- Completely flat commercial model – there's no limit to the number of apps you can model
The Cons
- No additional insight / visibility into network performance
- No historical data or analytics
- Automatic discovery requires communication between nodes when running discovery, although known dependencies can easily be added manually
Next Steps
What are you waiting for? VADA is easy to get up-and-running, with a free, 30 day trial of SquaredUp available from our website. Simply request a trial online and you’ll be sent everything you need to get started. Of course, VADA is just one of the many features of SquaredUp, so you’ll find there’s lots more for you to explore!