Blog
3 reasons why reporting SLOs at scale is hard
Since Google SRE popularised the use of Service Level Objectives (SLOs), there has been a lot of talk about what they are, why they are used, and how they are implemented. Adopting SLOs can provide much-needed visibility of service performance, but the larger your organization, the more challenges you might run into.
What are the unique challenges faced by SREs in larger organizations when measuring SLOs, and how can we overcome them?
Why do we need SLOs?
To understand SLOs, we first have to talk about SLIs. Service Level Indicators (SLIs) are the key measurements of how the service is performing, for example, the availability, response time, and error rate. SLOs add targets for those indicators. In other words, SLOs are an illustration of what “good” looks like.
Together, SLIs and SLOs allow us to focus on the results that matter, and provide us with a common language to communicate across different teams, and report results to stakeholders.
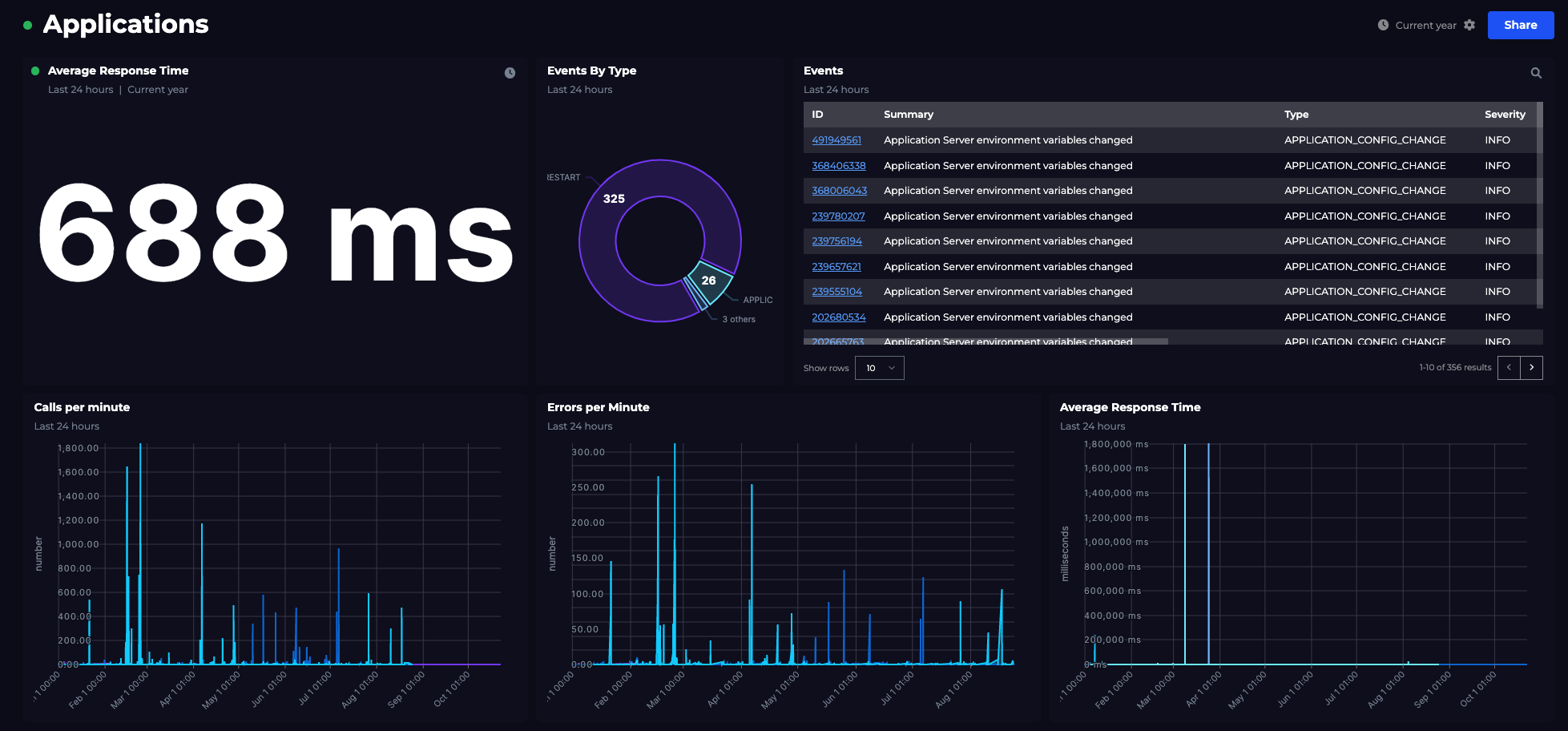
SLO reporting in large organizations
You'll find many recommendations on which SLIs you should choose, and some good examples on how to calculate SLIs. As always, though, the reality isn't quite as simple as the theory.
You'll often see SLIs explained for a well-defined microservice whose interface is an HTTP-based request-response API. In a large organization running a complex digital service the picture is messier.
Here are three challenges SREs hit when reporting SLOs in large organizations:
Challenge 1: Identifying services and dependencies
Scaling modern digital services has required moving away from monolithic architectures to more modular architectures made up of many microservices that can be deployed and scaled independently. Microservice architectures also enable development teams to scale – instead of one large development team all contributing to a single application code-base, smaller teams build and run smaller individual components, that are composed into more complex products and services.
This enables development teams to operate with low context – they don't need to understand the whole complex system, instead they can focus on just their piece of the puzzle, and how to build it the best way they can. This 'low context' way of operating is good for developers, but raises the question: who does know how the whole system works?
It's quite typical for large engineering teams to operate without having a catalog of all services, or how they fit together. This knowledge is held across many different teams. Which brings us to the next challenge.
Challenge 2: Reporting across multiple teams and tools
SLOs take some effort to design and implement. They depend on the nature of the service, and the observability data used for the measurements.
In large organizations this means that SLOs must be defined by the team that owns each service. They are the ones who have the knowledge of what the service is, how it works, and when it changes.
It's also often the case that they are the only ones with access to – and understanding of – the observability data needed to measure the individual SLIs. One benefit of the microservice architecture described above over monolithic architectures is that each development team can operate more independently, and this should mean freedom to choose the technology stack the service runs on, and the tools used to observe it.
Reporting across multiple services often requires manually requesting and collecting reports from multiple teams – a time-consuming, error-prone and ultimately frustrating process for everyone involved.
Challenge 3: Mapping to the business domain
So you end up with a list of SLOs by component service, but do they relate to how the business understands the service or, more importantly, how the end users experience the service?
SLOs are typically used for backend components; for the whole business service the performance is often more easily measured by incidents – reported by digital experience monitoring tools or end users, and captured in a service management tool such as ServiceNow.
To drive trust in the SLOs and focus development teams on the metrics that matter, SLOs need to be correlated with a business-level view of performance.
Building on a platform that scales
We don't have a silver bullet to the challenges outlined above. If we did make that claim then it would discredit the important role SREs have to play to champion the principles of reliability engineering, educate their teams on best practices, and drive the process changes that are needed across multiple layers of the organization.
What we do offer is the right platform on which to build a comprehensive SLO reporting strategy. SquaredUp is an enterprise observability portal that stitches data together across all teams and tools. It has three key benefits that help you overcome the challenges above:
- SquaredUp is the natural place for your development teams to store knowledge about each component and its dependencies. As a shared resource, SquaredUp becomes the go-to tool for sharing and finding service information across the whole organization.
- SquaredUp workspaces can consume data from any tool, so each team can measure and share SLOs using data from the tools they use day-to-day. This enables a unified view of SLOs that is independent of the tools used to measure them, giving you the flexibility to scale standardized SLO reporting across every service.
- SquaredUp integrates with service management tools, product analytics tools and business intelligence tools as easily as it does your backend observability data, allowing you to correlate data across the technical and business domains to create a joined-up view.
If you’re reporting SLOs across multiple tools and teams and need to put these into a business context then SquaredUp might be just the ticket. Sign up today or drop us a line.
Visualize over 60 data sources, including: