Stephen Townshend
Developer Advocate (SRE)
Developer Advocate (SRE)
The shift from traditional monitoring to observability is widespread, and necessary. It's the way we make sense of increasingly complex and distributed systems. But when we capture all this data at scale... what do we do with it all?
If this data itself had inherent value, we’d all be rich. But in the real world data does not provide us value until we can act on what it tells us.
In this article I explore three reasons why (at scale) we need a layer of summary on top of our observability data.

Consider a team of engineers who captures a bunch of telemetry data about their service or component. How easy would it be for an engineer from another team to come along and make sense of it?
They would probably struggle because they lack context about:
No-one can hold everything about a non-trivial distributed system in their heads. Especially not managers and leaders. Yet, observability data undeniably holds value beyond the team who collects it.
Large organizations tend to have many vertical layers of management. Products and services are also built and operated by many teams split across different divisions. Communicating across these boundaries requires interpreting data, applying context to it, and translating it to the right level for each stakeholder group.
To be fair, an engineer from another team could eventually make sense of your raw telemetry. Given enough time. But what about managers, product owners, executives, and other non-technical stakeholders? We can’t expect everyone to have the expertise to explore raw telemetry for themselves.

We live in the era of distributed services. The experience we provide our customers now depends not only on the reliability of what we build and operate, but also the many dependencies we rely on. Dependencies such as:
Because we rely on these services to provide our customers a great experience, we need to monitor them (despite not having access to the raw telemetry).
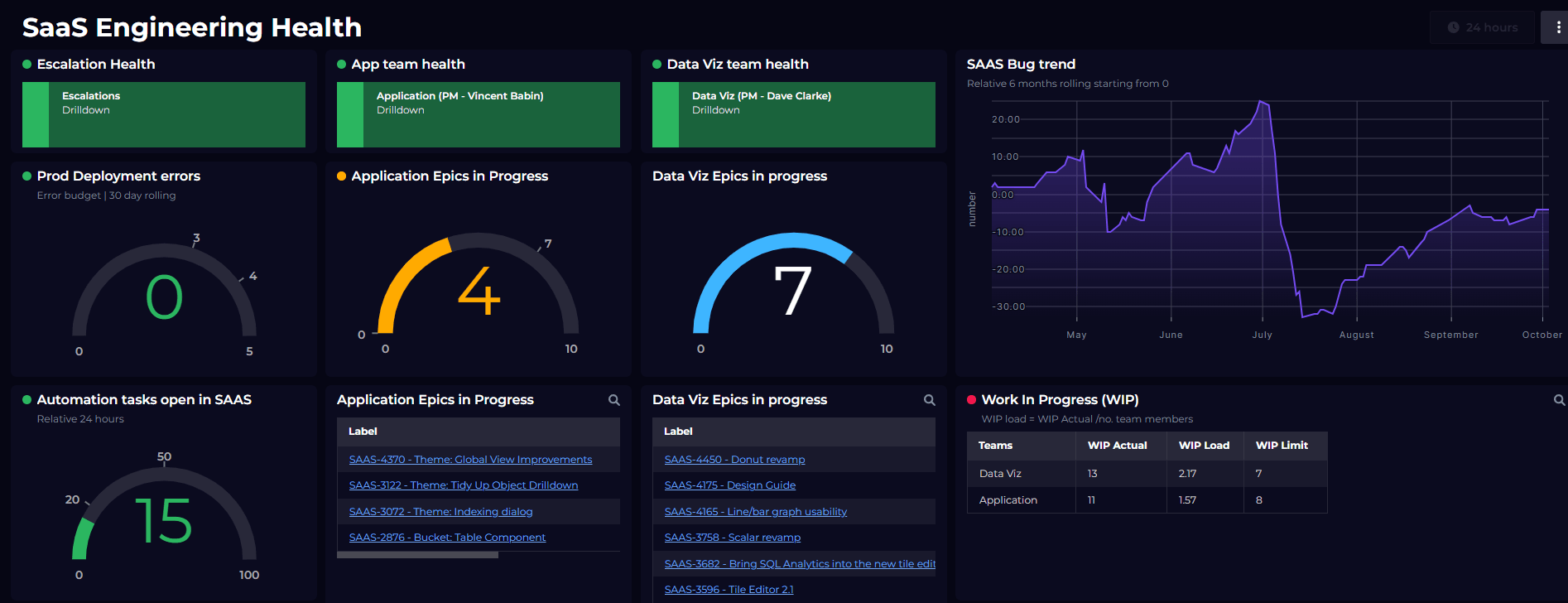
A health status or summary is a great start. Providing a status summary that can be consumed by upstream users goes a long way to building trust and self-sufficiency. How observable a product or service is should be one of the key criteria we look at when choosing vendors (or whether to integrate with an internal service).

According to the Catchpoint 2023 SRE Report there is a wide chasm between the points of view of leaders and individual contributors (ICs). The Toyota Way talks about all leaders (including the CEO) visiting the factory floor from time to time to keep connected to how products are being created, but clearly this isn’t as practical in a bank, a government agency, or a tech company.
Leaders need a clear view of what is happening so that they can make informed decisions. Engineers need to align the work they do with business objectives. So how do we bridge this gap?
One potential way to implement this flow of information is through the use of status roll-ups. As a hypothetical example:

However you achieve it, it's important to make sure that engineering work is contributing to the wider organisation and that leaders are aware of the day to day realities of how products and services are built and operated.
The challenge is providing enough information to make informed decisions, without overwhelming leaders with the full complexity of the whole system.
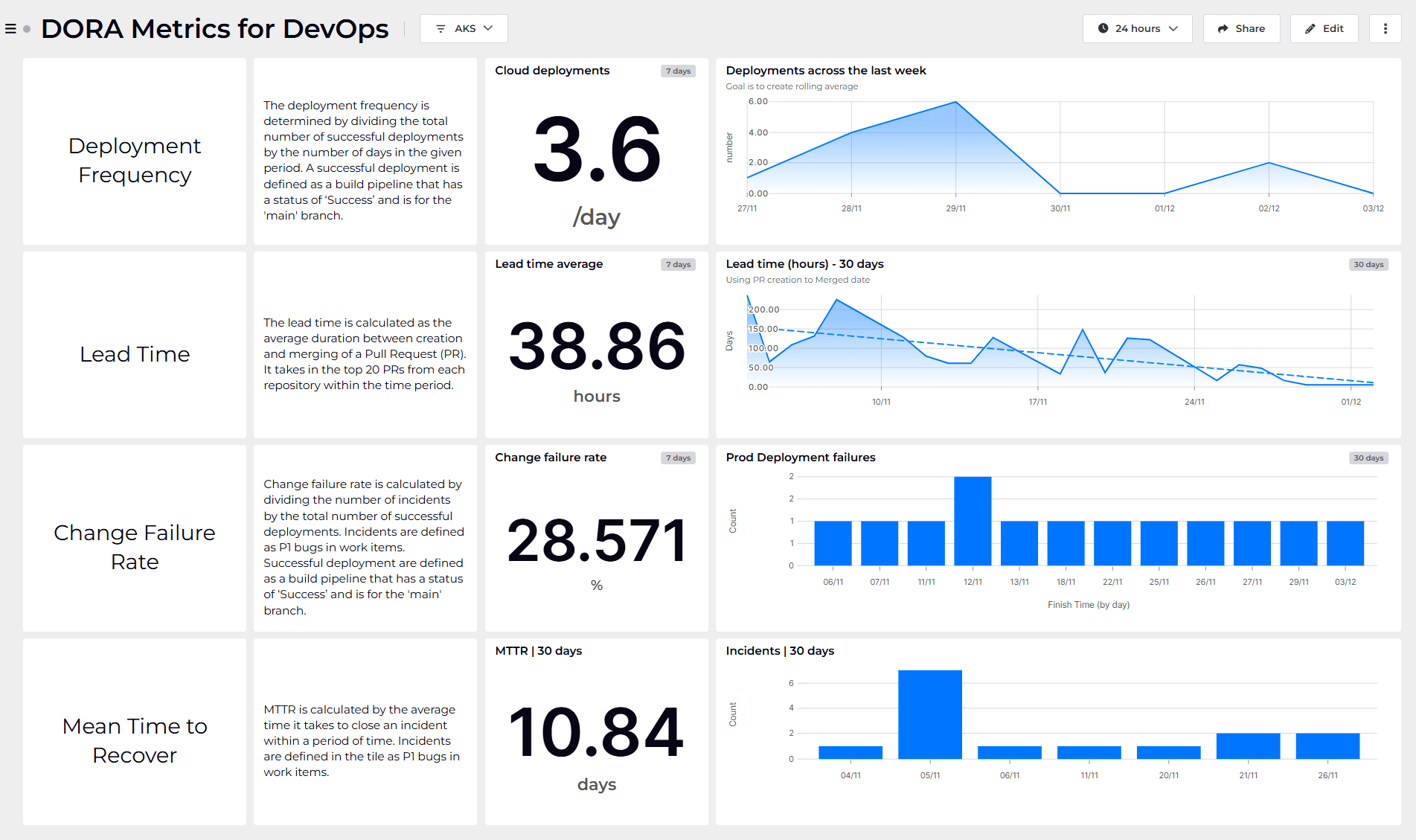
The data we collect to achieve observability has enormous value across the organization. To unlock that potential requires interpreting and summarizing the vast amounts of it.
Remember that not everyone has the expertise or context that you do. As engineers, it’s up to us to roll up key information to the people who need it in the organisation. Only then can we empower leaders to make well informed decisions about our products and services.
Fundamentally, it's about treating our observability as a product for the whole organization, not a private utility for one team's personal use. That requires a paradigm shift.
Developer Advocate (SRE)
Dashboard Story

Here's what our free tier includes: