John Hayes
Observability Advocate, SquaredUp
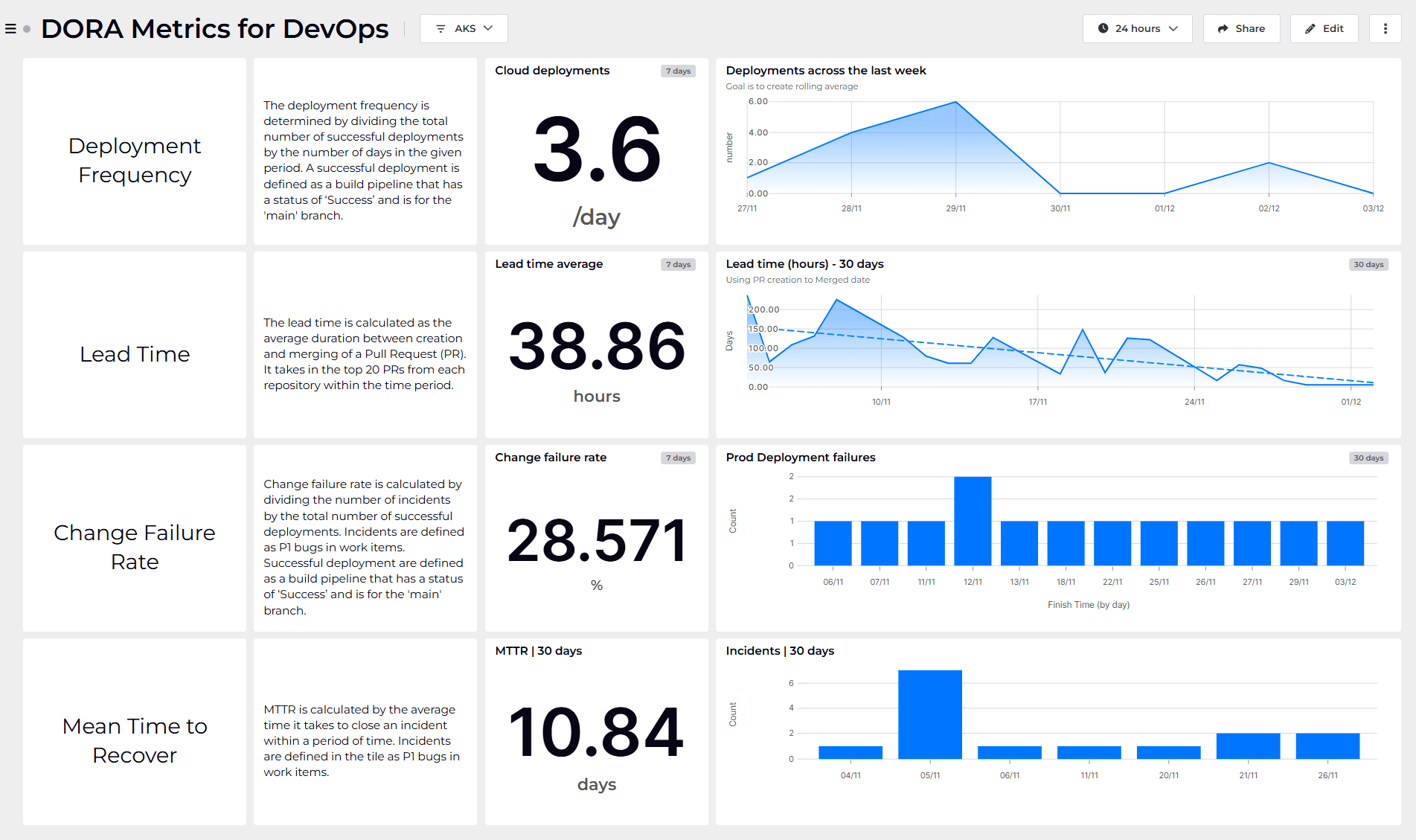
The principle of continuous improvement is central to the practice of observability. Naturally, within the data-driven philosophy of DevOps this implies an ongoing cycle of acting, measuring and improving. For many teams, the classic four DORA metrics are seen as a gold standard. As I discussed in a previous article, whilst DORA metrics are a great starting point for assessing your agile capabilities, they are not necessarily definitive. Indeed, as from 2021 DORA themselves added a fifth metric which covered reliability.
As your engineering team’s practice evolves, it is likely you will identify additional behaviours and patterns that you might want to monitor as you pursue the goal of continuous improvement. The great news is that, with SquaredUp’s deep and context-aware entity modelling, you can dashboard additional measures with ease.
In my experience as a Software and DevOps Engineer, I have found that Pull Requests can be overused. Whilst they may be valuable for major changes, dealing with a continuous stream of PRs for minor code tweaks can be a major drag on team velocity – and maybe even an indicator of a lack of trust within a team.
I have decided therefore that I am going to create a new metric in SquaredUp – Pull Requests Per Feature. In Azure DevOps, a Git commit can be linked to a Work Item such as a User Story and a User Story is a child of a Feature. We should, therefore, be able to join these three entities together within the scope of a single query.
At this point you could write your own client application that would query the Azure DevOps Web API, retrieve multiple different objects and figure out a way of storing, joining and presenting the data. Or, you could just use the SquaredUp Azure DevOps Data Source and be able to query and visualise your DevOps data within minutes. Let's see how it works...
For the purposes of this exercise, we will assume that your code is in an Azure DevOps Git repo and that you are using Azure Boards to manage your work items. We will also assume that you have created Pull Requests against User Stories in your Feature.
The first thing you will need to do is connect to your Azure DevOps instance in SquaredUp. If you are not sure how to do this, just follow the steps in this guide.
The SquaredUp Azure DevOps Data Source does not directly import all your Work Item objects. Instead, you can specify the objects that you want to work with in a Work Items Query and SquaredUp will pull in those objects. We have created a very simple object to return a list of our current Features:

In our backend data model for Azure DevOps entities, Pull Requests and Features will be loaded into their own virtual tables. Unfortunately, there is no common field for joining these tables in a SQL query. There is a simple, if not totally elegant workaround for this limitation. The data engine does create a virtual field called 'label' which takes the format of "{Work Item ID} {Feature name}". The workaround we have used for this is to add a tag to our PR's which adopts the same format:

If we look at our Azure DevOps Data Source in SquaredUp, we can see that the data it ingests is organised into Streams. We will be building our query from data in the All Pull Requests and Query Work Items streams.

Click on Dashboards/Add Dashboard and then click on the Data button. At the top of the screen, move the slider to Enable SQL Analytics. Then from the list of Data Streams click on All Pull Requests and then click on the Next button. Now select the Azure DevOps project which contains your repo and your Work Items. Now continue clicking on the Next button to progress through the remaining screens in the wizard. On the Timeframe screen the default is 24 hours, but we have changed this to 30 days. You will now see a preview of your data:

The dataset name defaults to 'dataset1' but we will change it to 'PR'.
Next click on the '+' symbol next to the word SQL at the top of the main panel - this will allow you to select an additional dataset for this tile:

Now click on the Query Work Items Data Stream and then click on the Next button. Select the relevant query from the list and then keep clicking on Next to reach the end of the wizard. This creates a second dataset for us. This time we will rename it to 'Feature'.
The two datasets we have created are analogous to SQL tables in SquaredUp. This means that we can now use the SQL window to query and join our data. Now try posting the SQL below into the SQL window and click on the Execute button:
SELECT Count(P.title) as [TotalPRS], P.labels as Feature FROM PR P
Inner Join Feature F on F. label = P.labels
Group By P.labels
You should now see a table something like this:

At this point you could also experiment with all kinds of visualisations such as gauges, bar charts, line graphs and more.
In this example we have used Azure DevOps as the source for our Work Items and our Git repo's. You can also apply the same principles for other stacks as SquaredUp also provides Data Sources for Jira, GitHub and GitLab.
This is a great example of the power of the SquaredUp data engine. It can extract data from dozens of third-party API’s and interfaces and provide a simple abstraction layer for manipulating that data with relatively simple SQL commands. It means that you can construct dashboard widgets that can surface datasets from heterogeneous data sources and join and visualise those datasets with great ease and without having to have any knowledge of the proprietary, underlying data formats and structures.
Observability Advocate, SquaredUp


Getting started with SquaredUp is free and easy. Our free tier includes: