John Hayes
Observability Advocate, SquaredUp

The evolution of observability into intelligent, real-time decision-making
Monitoring your systems isn't enough anymore. Neither is “asking questions about your system”. Operational Intelligence embraces observability to proactively deliver business insights, support decision-making, and accelerate innovation.
It seems that as the observability market grows and more and more products come into the space, the meaning of the term observability itself becomes more and more nebulous. Back in simpler times, any textbook you picked up would confidently inform you that observability rested on the three pillars of Metrics, Logs, and Traces. Now joined by the fourth pillar, events – which provides us with the handy acronym of MELTs.
Charity Majors at Honeycomb is credited with coining the term observability in the way we use it today. Her definition was rather more proactive and expansive than collecting signals and being alerted when things went wrong.
It was more about “being able to ask questions” about a system, to explore and delve into the unknowns and the unknown unknowns. In general, this could still be seen as defining observability as a purely technological practice.
That is, it may have signalled a move from a reactive posture to a more open-ended one of discovery, but this was still, ultimately, for the purpose of understanding the dynamics and flows of an IT system.
Many commentators on observability practice highlight the need for organisations to build their observability infrastructure within the context of an overall strategy. In general this is defined within a technological framework, i.e., what are the applications I need to observe? What are the technologies I need to observe? What are the outputs I want to measure? How will I manage alerting? What is my level of in-house skill? How will I implement instrumentation?
These are all genuine and important concerns, but they are rooted in the realm of the technical. For me, if the transition from monitoring to observability marks a transition to a more active process, then it is one that also encompasses a cultural aspect. It works best not as a purely technical pursuit delegated to an observability or NOC team but as a data source for feeding loops of continuous improvement across numerous business domains. This is where observability ceases to be about monitoring or about MELTs and instead lays a golden path to Operational Intelligence.
In a sense, this ties in with another question raised by Charity Majors, this time in her recent article on observability costs. A lot of articles on this subject follow the pattern of citing various egregious examples of bill-shock and then either selling you on their own product or offering some advice on reducing your observability costs.
Majors takes a broader perspective and says that observability can be seen not just as a cost, but as an investment. If you want, you can regard it as a fire alarm but it can also be used to provide feedback to help you improve services and achieve a competitive edge. This means reconceptualising your observability tooling, thinking of it as a catalyst for improvement and not just a cost sink.
It is not just about re-thinking the function and position of the tech though. It is also about re-thinking cultures and practices. We can see this in the implications of advocating “wide events” as an enabler for “asking questions about a system”. This is a pattern which takes a holistic and contextual view of telemetry. It's fundamental unit of analysis is the transaction and it bundles all of the relevant measures and records of that transaction into an arbitrarily wide event.
What are the attributes that constitute an arbitrarily wide event? Well, the answer as is often the case is “it depends”. This is an activity where we have to stop and think and inject some human intelligence. The people who instrument the application need to have an understanding of processes and of what are the relevant attributes that can and should be bundled together to provide a wide context for subsequent exploration.
This kind of represents a radical flipping of the narrative on what we expect from a new IT system - i.e. convenience and automation. It requires a lot of time and intellectual effort - which goes directly against the grain of the "don't make me think mantra".
Having engineers stopping and thinking is almost anathema to shops that take mechanistic views of "developer productivity". It also underlines the fact that a successful observability implementation is never just a matter of buying some observability machinery and plugging it in.
Getting your observability up and running is not just a matter of configuration; it is a matter of adaptation and requires a mentality of stewardship. This requires an investment in time and money, but also a mental investment. A belief that observability is part of your business process, not just an insurance policy.
A great example of this philosophy in microcosm is the use of SLOs. SLOs are selective, intelligent and business-oriented measures. What do we mean by this? Well, in terms of being selective we mean that they prioritise some services over others. Not every service or system is critical. Some outages may have a catastrophic business impact, others may have no impact on the customer at all. They are intelligent because they take a realistic view of business tolerances. They are business focused because they are determined on impact to the customer rather than the internal state of a particular system component.
For an example, an SLO that 99% of video playback sessions should start within two seconds of the Play button being pressed is a metric which focuses on the experience of the end user rather than the performance of a particular code service or backend server.
In a recent LinkedIn post, Dash0 CEO Mirko Novakovic cited the example of a RyanAir KPI. It was a measure of tickets sold. Although this seems like a purely business metric, if the figure dropped it would also figure an investigation of their software systems. It is a practice which weaves together the two strands of observability practice and business value.
Operation Intelligence takes this sensibility to a higher level, to enable teams to leverage their telemetry and system data into analytics that can drive improvements in business performance.
A classic example of this is the use of DORA metrics – a set of empirical and essentially technological measures for ramping up quality and reducing software delivery cycle times. There are also many different kinds of high-level metrics which can be used to gauge different spheres of business performance. You can use tools such as SonarQube and Snyk which will provide feedback on key security indicators such as:
Equally, FinOps tooling is playing an ever more important role in measuring cloud expenditure. This is not just a matter of retrospective analysis of monthly bills. It can also be used to track daily trends so that excess expenditure can be spotted quickly and misconfigurations can be addressed before large bills have been run up. FinOps tooling can also suggest optimisations that can be implemented on a continuous basis. A similar principle can be applied to many other domains such as managing customer support calls, analysing sales funnels, or monitoring real flows from IoT devices.
There are numerous other areas where these kinds of insights can be applied:
Understanding feature adoption and user behaviour: Observability tooling can be used to analyse which customers are using newly shipped features, how their usage patterns differ from those who abandon the feature, and gauge new feature adoption
Strategic decision-making: Observability data can inform sales and executive teams about which product features are most heavily used, need the highest availability targets, or are most critical for strategic customers
Enhanced customer experience and retention: Many platforms now include RUM capabilities, which provide detailed analytics on user experience by capturing user-side issues like page load times and client-side errors
Cost management and operational efficiency: Profiling data, which provides detailed technical views of resource usage (e.g., CPU, memory), can lead to significant performance and cost improvement.
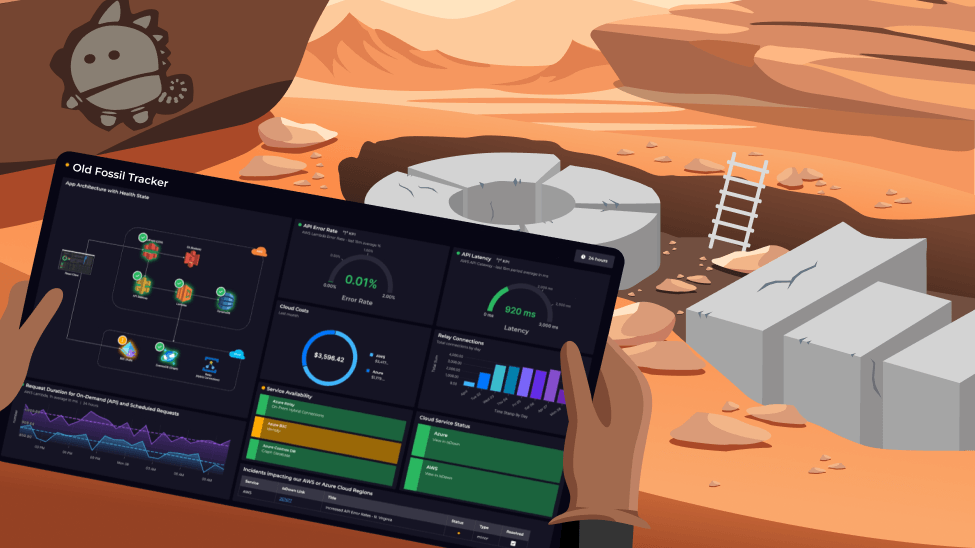
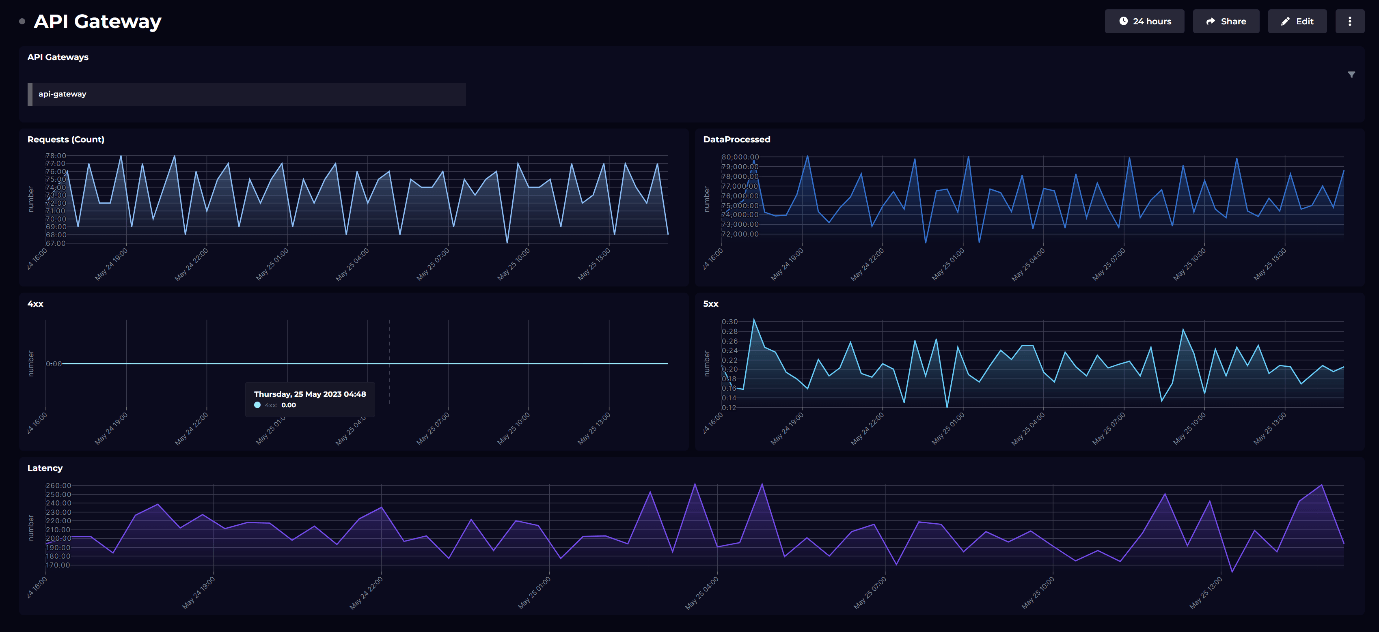
At SquaredUp, this approach is foundational to what we do. We see Operational Intelligence not as an activity that is distinct from observability or more important than observability. Instead, it is a set of practices that encompass observability tooling and insights to create business value. Most importantly, this aligns with the feedback we receive from our customers - dashboards that use key metrics to visualize process health and performance in real time help them to drive continuous improvement.
If you want to keep up with the discussion on Operation Intelligence, you can subscribe to our Operationally Intelligent podcast series, where our host, Adam Kinniburgh, invites expert practitioners and thought leaders to share insights on harnessing data to generate business value.
Observability Advocate, SquaredUp

Getting started with SquaredUp is free and easy. Our free tier includes: