Stephen Townshend
Developer Advocate (SRE)

Developer Advocate (SRE)
A new year has started and I've been pondering my hopes and dreams for the year to come. In the world of SRE, observability is the most prominent pillar of my work. So, I decided to drill into the topic of observability and what I'd like to see happen in the industry in 2023.
Rather than focusing on any tool, technology, or methodology, I'll be exploring concepts that can be broadly applied in any organization.
In this article we'll cover:
I also share my personal goals to learn more about distributed tracing and monitoring serverless architectures.
From my own experience, organizations are still primarily focusing on observability as way to understand technology. For example, faster incident remediation, better understanding of complex distributed systems, and tracking system or service health. I think observability can be so much more.
When you get to the point where you are instrumenting your code to expose custom metrics, the next logical step (in my mind) is to start exposing business and customer insight. The power of doing this as part of observability (rather than something the "data and analytics" team does) is that you have insight in real-time, and you can track it alongside your technical metrics to see how they interact.
Organizations have objectives, things they want to achieve in the next quarter, year, or five years. Observability is a way to track whether or not the organization is trending toward that objective or not. Here are some examples of business or customer level insight you could track using observability tooling:
I'd like to see a lot more of this in the industry. To get this level of insight in real-time it's not enough to install a tool and hope for the best, it requires forethought and instrumentation of code (in most situations). However, the pay-off is immense. We live in the Digital Era. Experimentation is the only way to negotiate our way through the unknowable unknowns. Observability can be the way we verify the outcome of those experiments.

For the most part, the observability torch is being carried by a smallish number of "observability people". If you go and speak to developer or other engineering communities, it's often not on their radar or not a major consideration. The problem with this is that observability isn't for "observability people"... it's meant for other developers and engineers. So how do we get more buy-in from the wider technology community?
The first thing that comes to mind is that we need to make observability tooling and concepts as accessible and easy to understand as possible. Yes, implementing observability is complicated, but it's my job (and the job of other "observability people") to make it simple enough and approachable enough for others to adopt.
The second thing is that we need to demonstrate the value of observability and, even better, make it engaging and enjoyable to work on. If we try and impose observability as a mandatory checkbox for teams to tick off before they ship code, there's not going to be any internal ownership for it. It will quickly become yet another piece of technical debt that lies forgotten on the side of the road. Until a major incident occurs and then, for a short burst, everyone will scream for better observability again.
This isn't an easy problem to solve, but I think it's fair to say we have a long way to go as an industry and a community. My resolution would be to find a language and a medium to uplift observability to a place where it's no longer niche, but mainstream. Then, like testing, it'll become part of what product teams think about and include in their work.
As a performance engineer one of the most important lessons I learned was the power of raw data, and the pitfalls of aggregating. Back in 2017, I wrote an article called Let's Talk About Averages which introduced the usage of scatterplots of raw data for performance test result analysis, and showed some of the ways that aggregates (averages and percentiles) can be misleading. I haven't seen any analysis of raw data at all since transitioning to the field of SRE, and I think that's a huge missed opportunity.
In observability, the signal that lends itself to raw data analysis is logs (which are effectively records of events). The reason we tend not to analyse raw data at scale is just that, the scale. If you captured every log line from a massive scale application then the data storage costs would be out of this world and the performance of trying to retrieve and plot it all would be terrible.
However, I can see ways in which we could use it. What if we captured all the raw data once a day for 20 minutes? Then we could analyze this data in a scatterplot and compare the system behavior day on day. You don't truly understand how a system is behaving until you look at the raw data, and I guarantee there are a lot of weird patterns of system behavior happening out there in the world that are hidden from view because only aggregates are being captured or looked at.
I'd like to see raw data being used, in some capacity, in our observability. If we don't use it at all then we are filling in the gaps with assumptions. As Avishai Ish-Shalom put it in this podcast episode by OpenObservability Talks, aggregating our metrics is like lossy compression. If we want to zoom into the detail of what's really happening, sometimes we need that raw data.

The observability community is abuzz with the OpenTelemetry project. If you haven't heard of it before, it's an open source specification for capturing metrics, logs, and traces, processing that data, and pushing it to the tool(s) or backends of choice. The major selling point is that you can instrument your code once and have compatibility with a variety of open source and commercial tools in the market for visualization and analysis.
OpenTelemetry (OTEL) is a work in progress. At the time of writing this article traces are fairly mature, metrics are in progress, and logs have a way to go. There is also an open source tool called the OpenTelemetry Collector which is capable of scraping or receiving telemetry data, processing or filtering it, and sending it on to your tool of choice.
My own experience with OpenTelemetry is that despite the huge buzz, it's extremely challenging to find simple and easy to digest content to help you get started. Just last week I spent time trying to instrument some Node.js code with custom metrics using the OpenTelemetry libraries, and ultimately wasn't able to get anything working. In comparison, it took me just a couple of hours to create and expose a couple of metrics using the Prometheus prom-client package.
If OpenTelemetry is going to take off it needs clear documentation and other resources to help people get started. It also needs to be simple enough to implement that you don't need to be a staff engineer at Google to implement it. I think in my case I tried to use it too soon, before metrics were in a mature state.
During the fifteen or so years of my career I have had extensive experience working with both logs (or events) and metrics, but distributed tracing is something I am not that experienced with. I would like to get myself up to speed.
I'd like to implement distributed tracing using a few different tools and approaches, and investigate the use cases. And of course, create helpful content to help others begin their tracing journey.

I hear so much about OpenTelemetry, so now I'd like to put it to use. There's a few different things on my radar:
I'm even getting involved in the OpenTelemetry community and am planning to intend the APAC working group sessions starting in January 2023.
Next year I am going to be on-call to support SquaredUp's cloud product. The software is mostly built on AWS Lambda which is a serverless compute platform. I haven't worked much with serverless before, so I have a lot of questions:
I don't have the answers, but I'll soon be diving into this space. As always, I look forward to sharing what I experience, learn, and probably all the things I fail at along the way.
If I had to strip back everything I just said down to its essence... I would say my New Year's resolution is for observability to be implemented with the business and customer in mind. Observability for observability's sake is a waste of time and effort. It should always be about achieving outcomes.
Secondly, let's keep simplifying observability and making it as approachable as possible. This will help organizations and engineering teams everywhere to work more efficiently, effectively, and keep them focused toward business and customer outcomes.
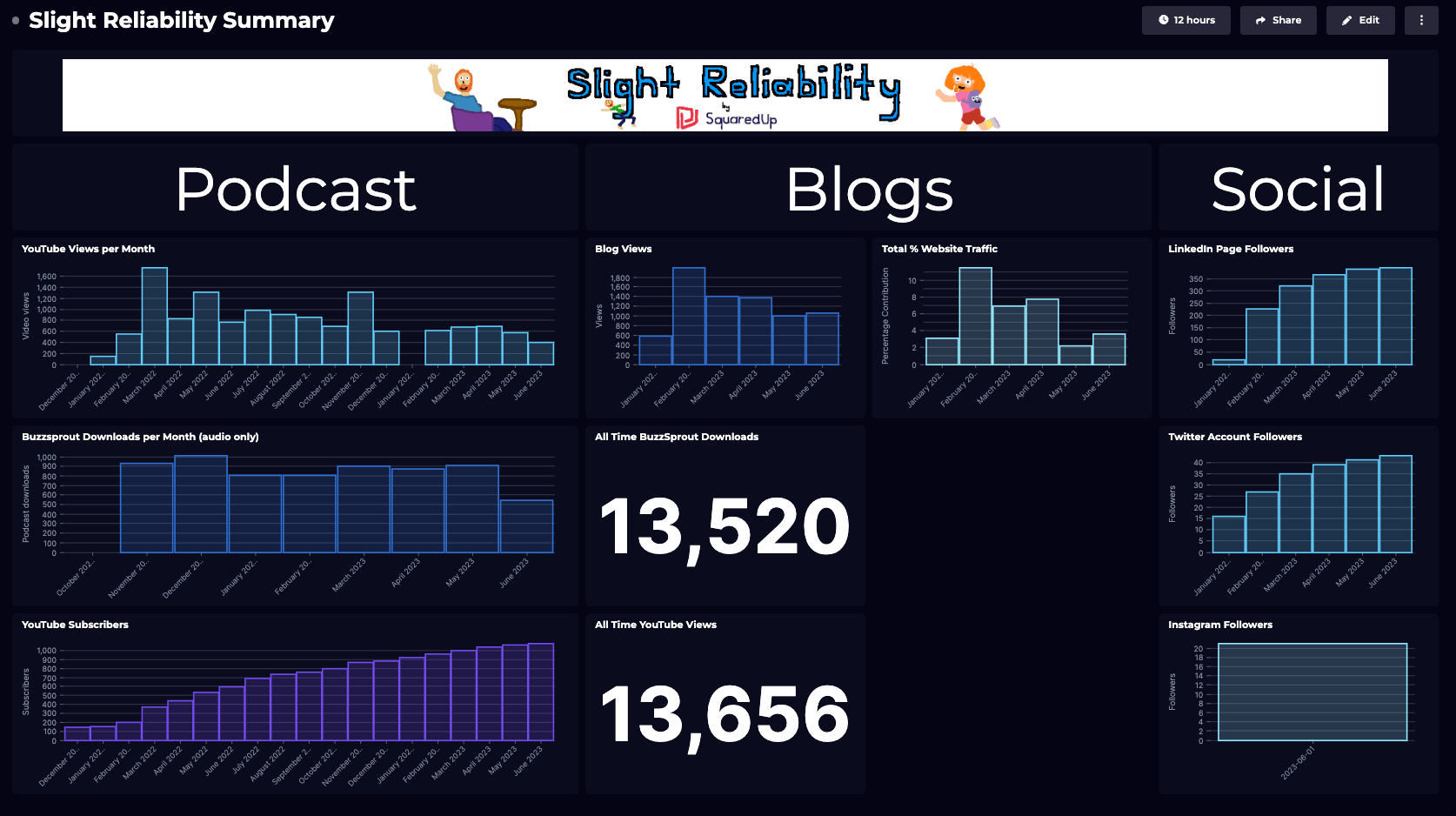
This article was inspired by episode 37 of the Slight Reliability podcast which was titled "Observability New Year's Resolutions with Henrik Rexed".
If you want to read more about the power of raw data (and the pitfalls of averages and percentiles) you can check out the article I already mentioned (Let's Talk About Averages), Performance Testing: Act like a detective. Use raw data! by Stijn Schepers, or How to get a better understanding of your performance test results by Joey Hendricks. Although these articles all talk about performance testing, the concepts are universal.
Developer Advocate (SRE)

Here's what our free tier includes: