
Adam Kinniburgh
VP Innovation, SquaredUp



VP Innovation, SquaredUp
Join the SquaredUp Tech Evangelists on their Azure Monitor journey as they learn all there is to know about the platform. For a brief overview of the series, check out Sameer’s intro note.
In my last post I walked through a brief introduction to Application Insights, and application performance monitoring (APM) tools in general, and hopefully the simple outside-in availability test I concluded the chapter with has been a useful starting point for you on your APM journey.
In this post, I’m going to dig deeper into Application Insights and walk you through an Azure APM use case that should make the purpose of Application Insights really clear. We’re going from outside-in to inside-out, and then pairing them up to give you complete visibility of your application.
When I think about monitoring in the infrastructure world, there are typically two options that most tools will offer. One… install an agent, or two, use a protocol like SNMP. In the first case, we’re allowing our monitoring platform to gather data by putting some specialised instrumentation inside the device in question to do the work of collecting data and sending it to the platform. In the second, we’re making an outbound connection from the monitoring platform itself so that it can gather data from the outside.
When we’re talking APM, the concepts are thankfully quite similar and I’ve always found the terms outside-in and inside-out to be fairly understandable. The availability test we set up in the last post is performed by Azure from any of the global datacentres you choose, and a test like this is measuring your application’s performance from the outside. Today we’re going to discuss the other option and add some instrumentation into our application to measure it from the inside.
Before we get into the nuts and bolts, it’s worth just quickly addressing why this is such an important step to take when it comes to application monitoring. Firstly, just like infrastructure monitoring, there’s only so much you can observe from the outside. Second, if you want to know why something isn’t working as expected, you need to get into the process and see where the bottleneck is. When your car won’t start, it’s extremely unlikely that you’ll figure out why just by staring at the hood.
Let’s start with something that should be pretty familiar to all you monitoring enthusiasts… an agent. In the world of APM, where we’re always talking about software, we typically talk about an agent as performing “codeless monitoring”, or in other words, enabling application-level monitoring without touching the app’s code. Most APM tools will offer a solution like this but ultimately, it comes down to how your application was developed and where it’s hosted as to whether or not this will work for your application.
Pointing out the obvious, in order to use an agent you need to be able to install the agent in the first place. If your application is hosted in a PaaS / serverless environment, your codeless options might be limited. Where codeless monitoring is most likely an option is when you have access to the underlying infrastructure i.e. the server that hosts the app, or where you’re using an APM tool that was designed specifically for your technology.
Talking specifically about Application Insights and Azure then, codeless options are only getting better. You can deploy the agent to a VM as an extension right from the portal, and they also offer one-click installation for various app-centric resource types like Web Apps. So, if you’re reading this post because you’re being super proactive in advance of an upcoming project, Web Apps make life really easy when it comes to Application Insights as you get the option to turn it on and provision a new instance right in the deployment wizard. You can also do it via ARM templates so there really is no excuse to forget about it.

We’re going to focus on Parts Unlimited for a minute, which is a simple .NET application running on an Azure Web App. When it was first deployed, Application Insights wasn’t enabled. Enabling it after the fact is really simple though, so let’s do it now.

Application Insights is in the left-hand menu under Settings and when you drop into that blade, you’re presented with a single option, and that’s to turn it on.

Clicking the button opens out some more settings, and the first choice is whether you want to create a new instance of Application Insights or link to an existing one. In my case, I already have an instance I want to use for this Web App, so I’ve selected it.

Scrolling down reveals a few more options, and these are starting to sound what I’d firmly call developer-y. The first option I have to choose is which language my app uses. As I mentioned before, Parts Unlimited is a .NET application so it appears as though I can make this work without needing to install the Application Insights SDK into my app like I would with Node.js, Java or Python. The tooltip below would suggest that Microsoft are working on codeless options for those stacks too though, which is great to hear.

In the next section, for my case I want as much information as Application Insights can muster, so I’m going to leave the default option under Collection Level set to Recommended. There are some useful links next to each option in this panel so I’d recommend some further reading at this stage.

By leaving Collection Level set to Recommended, the default option of On is set for Profiler and Snapshot Debugger too. These two tools are at the heart of APM as they’re responsible for surfacing code-level metrics and identifying problems with your application, as well as areas for improvement. This is the inside part of inside-out monitoring.
Now that I’m done, I simply click Apply at the bottom and Application Insights will do the rest. My Web App will be restarted but as it comes back online, the Application Insights instrumentation will kick into life and start analysing my application’s behaviour. This is often referred to as “runtime” instrumentation.
Before I move onto the next section, I just want to give you a quick pointer for those cases where your application is running on a VM. Like in the example above, there’s already a solution for you where your app is .NET-based, and you can enable it during or after deployment. Simply find your VM and click on Settings > Extensions, then Add. You’re looking for the Application Insights Agent, which at the time of writing is still in Preview.

For any other deployment scenarios, I’d recommend checking out this article from Microsoft which covers the VM agent in more detail, including how to deploy it manually to VMs that aren’t running in Azure.
https://docs.microsoft.com/en-gb/azure/azure-monitor/app/status-monitor-v2-get-started
Code-based APM requires modifying your application so that it can gather and send data to Application Insights by itself. As a former sysadmin, I’m perfectly comfortable with all the concepts in code-based APM but when it’s the only option and it’s a critical application, I’d rarely have been in a position to do this without assistance from the app’s developers anyway. So, let’s talk about code-based APM in brief and I’ll do my best to point you in the right direction.
We saw in the last section that codeless, or runtime, monitoring for my Web App is only possible with Application Insights where the app is .NET and running on a specific set of technologies. If your app doesn’t meet these criteria, you need to take further steps. To put it simply, we need to load the instrumentation as part of the application rather than purely at runtime, and it’s the Application Insights SDK that brings the magic here. I’m not going to go into the specifics of using the SDK but please check out the following article from Microsoft which covers a number of step-by-step scenarios.
https://docs.microsoft.com/en-us/azure/azure-monitor/app/nodejs
Following either of these routes will really bring Application insights to life so I’d always recommend putting in the work to get it set up. Like I mentioned at the beginning though, not being developer-y myself I’d have struggled to implement the code-based option without making a new friend along the way.
I want to start this last section by making a quick comparison between “classic” outside-in monitoring and this brave new world of inside-out APM. I mentioned at the start that you can’t tell why your car won’t start just by staring at the hood, and here’s what I mean.
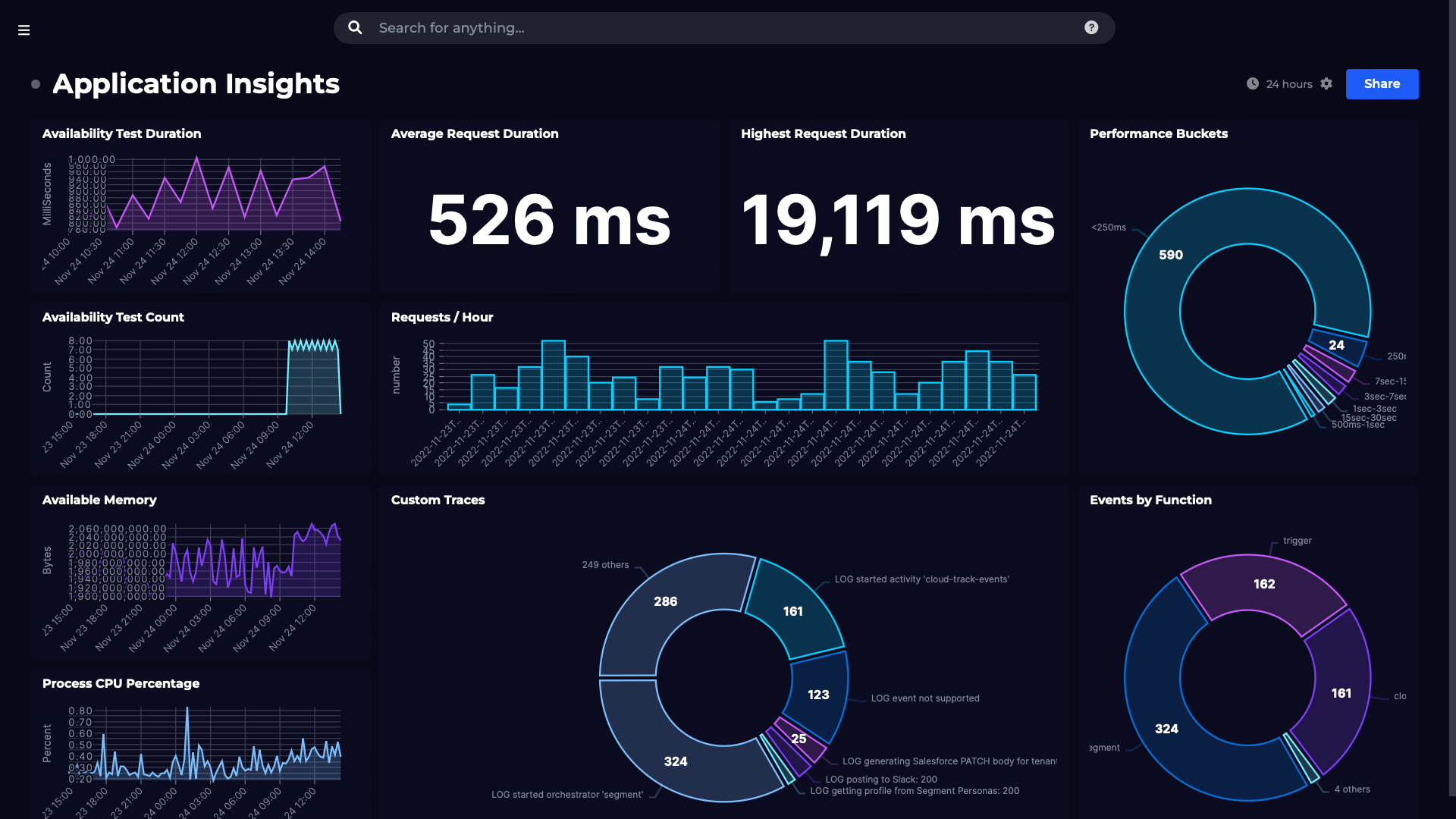
In the screenshot below, on the left we have an Application Insights dashboard where I’ve only configured an availability test. On the right, we have codeless monitoring across all of the nodes that the app relies on. In both cases we’re seeing external availability, but by going “under the hood” we’re also seeing code-level exceptions, the response time of the internal processes, and the number of requests being received.

Even if you don’t know what all these metrics mean, I’m sure you’ll agree that I have way more data to use in the example on the right than I do on the left, so when I’m trying to figure out why my availability test is all over the place I have a bit more to go on. And even if I can’t get to the exact issue myself, I should be able to narrow down the problem so that I can ask the right person for help.
The good news in my case is that a few trends in the internal data seem to correspond to the drops in the external availability test so I’m leaning towards the issue being with the application itself, rather than any external factors like networking, DNS, load-balancers etc. Without this little bit of extra data, I’d have a much longer list of possible causes to look into.
It’s not offline all the time though, so what’s actually going on?
A great starting point is Smart Detection, which proactively analyses your application’s telemetry and can warn you about potential performance problems and failure anomalies. You’ll find it in the left-hand menu under the Investigate section.

Something I find useful is that the default rules that Smart Detection checks against tend to focus on patterns and trends rather than single events. One failure might be nothing to worry about, but a number over a period of time could indicate a problem. Maybe a consistent number is acceptable but a rising number is worthy of concern. Smart Detection should have you covered for these situations where patterns and trends are important.
Smart Detection has raised three issues in my case. Firstly, that a “significant increase” in System.OutOfMemeryException errors are being recorded. Second, that a rising number of requests are returning a HTTP 500 (internal server) error, and lastly, that calls to my application’s index are taking an increasingly long time to complete. Potentially some good starting information for me to look into.

Next I’m going to look into exceptions and see if there’s anything obvious in there. I can do this from the Failures blade in the Investigate section of the left-hand menu.

From the Exceptions tab, I can view any issues being flagged and start to correlate their frequency against other metrics like request count, memory, CPU etc. The specific exception ID’s are also listed alongside the number of users effected and the total count of those exceptions in the chosen time period. I’m seeing one exception that is particularly prevalent in comparison to the others and looking at the whole picture, I’m getting an idea that the problem lies with a Windows service that runs between my web front-end and database back-end.
Now just in the interest of fairness, I was only able to make my last assumption for two key reasons... (1) I already know a lot about how this app works, and (2) I know who to Slack depending on the circumstances. Ultimately, it’s a combination of these things that will lead me to the root cause but if I hadn’t had a few pointers from Application Insights first, I wouldn’t have gotten to the right person so quickly.
The case I’ve laid out here is a fairly simple one when compared to the depth of insight that you can achieve with a well-implemented APM tool. Using a codeless option will help to shed some light on issues with your applications and going code-based will let you take that even further. Application Insights is capable of a lot more but I’m going to leave it here for today and hope that you’ve had a good taste of what is possible with a tool like this.
In the old days, troubleshooting an outage in a distributed app would have involved calling ten people into a room for a world-class game of finger-pointing. And while I didn’t get to a specific root cause myself with my simple codeless setup, I was able to shorten the list of people, find the right expert, and reduce the time to resolution. Application Insights, and APM tools in general, are not a complete solution for monitoring and in most cases they won’t solve all your problems. But, by combining the application-level data with an outside-in test, and putting that into context by also considering the performance of the underlying platform, you can really start to master application monitoring.
We’ll discuss a new topic each week, so stay tuned. Drop your email address in the box below to get notified with each new post, or join our dedicated Slack channel to be a part of the discussion.
VP Innovation, SquaredUp

Monitor your Azure environment, including VM, Functions, Cost and more.
Dashboard Story
Dashboard Story
Dashboard Story

Here's what our free tier includes:
